Credit Score Prediction using Machine Learning In today's world, credit scores are essential to determine creditworthiness for lending institutions, and they impact everything from getting a mortgage to renting an apartment. With the rise of big data and machine learning, the credit scoring process has been revolutionized, making it more accurate and efficient. Machine learning algorithms have the ability to analyze vast amounts of data and provide more accurate predictions than traditional credit scoring models. This article will explore credit score prediction using machine learning, including its benefits and challenges. Credit Score and its Importance A credit score is a numerical representation of a person's creditworthiness based on their credit history, income, and other financial factors. It is a critical factor for lenders and credit card companies when deciding whether to approve a loan or extend credit. A credit score ranges from 300 to 850, with higher scores indicating better creditworthiness. A good credit score is typically above 700, while a score below 600 is considered poor. Benefits of Machine Learning in Credit ScoringMachine learning algorithms have revolutionized credit scoring by providing more accurate predictions of creditworthiness. Machine learning models are trained on vast amounts of data, enabling them to identify patterns and make more accurate predictions than traditional credit scoring models. Machine learning algorithms can also take into account a broader range of data, including non-traditional data sources such as social media, to make more accurate predictions. One of the main benefits of machine learning in credit scoring is its ability to reduce bias. Traditional credit scoring models often have inherent biases based on factors such as race or gender. Machine learning algorithms are designed to be unbiased, as they are trained on data and do not incorporate any preconceived biases. This results in fairer credit-scoring decisions. Machine learning algorithms are also more efficient than traditional credit scoring models. They can analyze vast amounts of data in a matter of seconds, providing near-instantaneous credit-scoring decisions. This makes the lending process faster and more efficient for both borrowers and lenders. Challenges of Machine Learning in Credit ScoringWhile machine learning has many benefits for credit scoring, there are also challenges to consider.
Python ImplementationNow we will try to implement it in the code. ObjectiveBased on a client's monthly customer profile, the goal is to estimate the likelihood that they won't pay off their credit card bill in the future. The binary target variable is derived by tracking performance over the 18 months following the most recent credit card statement, and a default event is deemed to have occurred if the consumer does not make the required payment within 120 days of the statement date. About DataEach customer's aggregated profile characteristics at each statement date are contained in the dataset. Features fall into the following broad groups after being anonymized and normalized:
The following features are categorical:
Output:  We have 5531451 rows and 190 columns in the Training dataset. Output: 
Output: 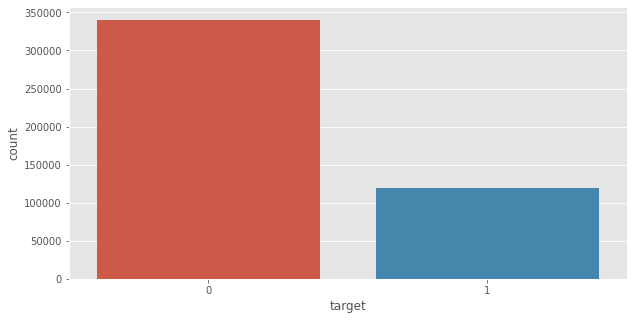 Here ,0 --> Non Default and 1 --> Default
Output: 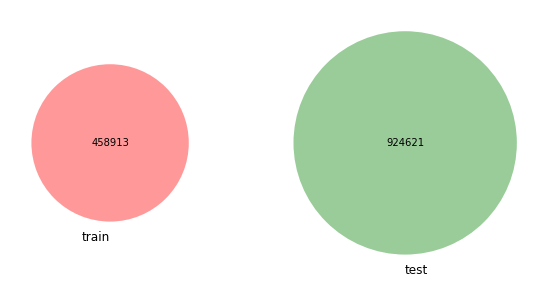 We can see that there are no user intersections in the train-test data. Output:  Output: 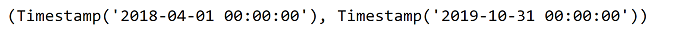 Also not intersect the timeline. Output: 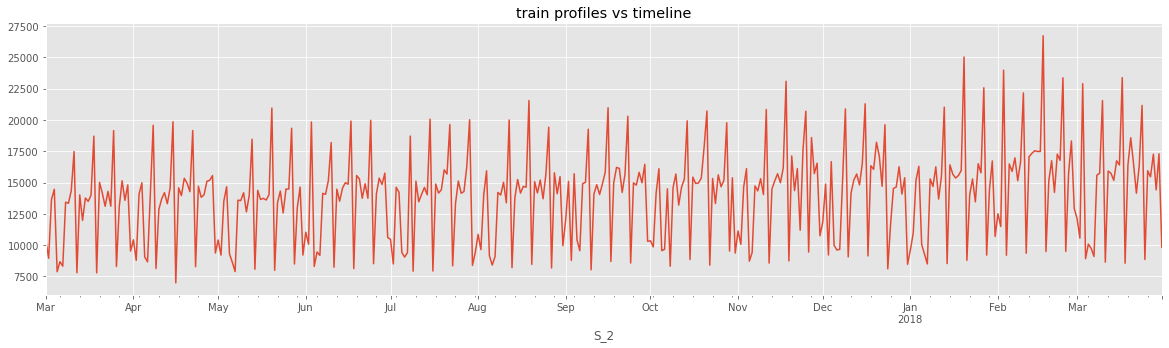 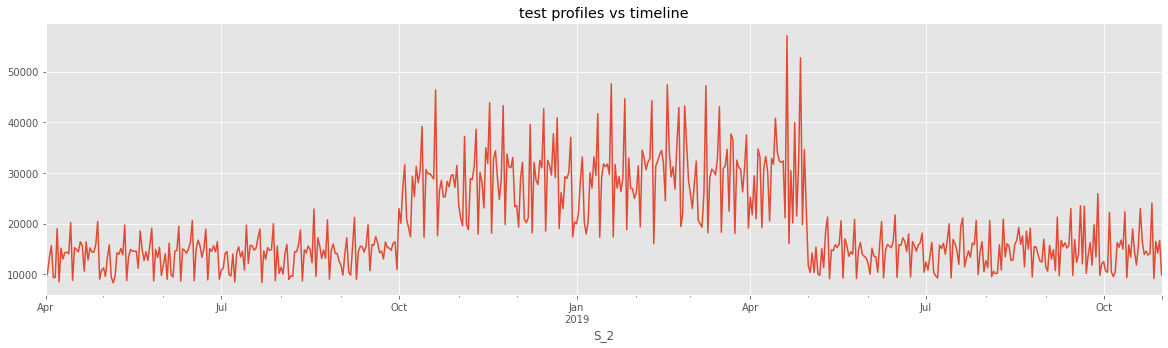 We can see that test profiles increased from October to April while train profiles remained consistent. Output: 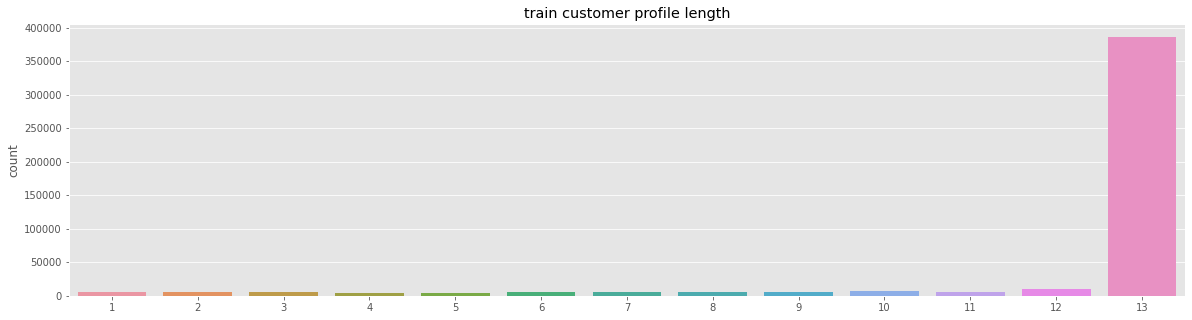 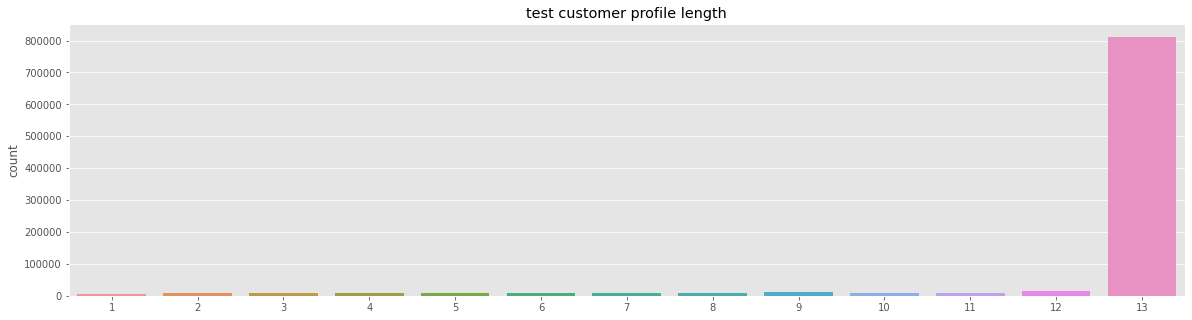 We can see that the distributions of the train and test profile lengths are similar.
Information value is one of the most useful techniques for selecting important variables in a predictive model. It helps to rank variables on the basis of their importance. 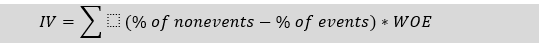 If the IV statistic is:
Now, for selecting features, we are calculating IV values for each feature. Output:  Output: 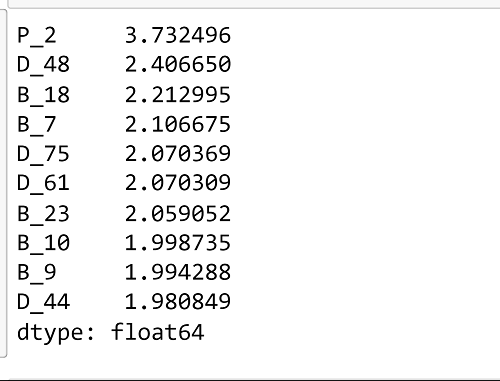 Output: 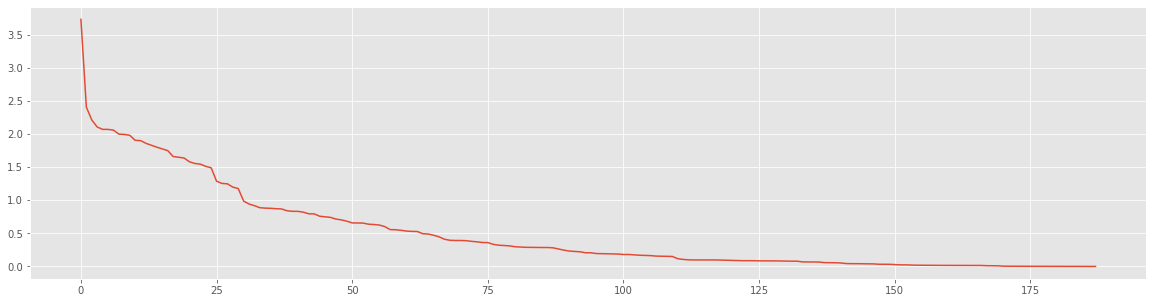 We can observe that the top 75 features have > 0.5 IV value, so those top 75 IV value features are strong predictors. Weight of EvidenceThe weight of evidence indicates how well an independent variable may predict the dependent variable. It is frequently referred to as a measure of the separation of good and poor consumers because it developed from the realm of credit scoring. Customers who miss a loan payment are referred to as "Bad Customers." and "Good Clients" are those who repaid their loans. 
Steps of Calculating WOE
For one feature, we'll try to describe woe values and a woe plot. Output: 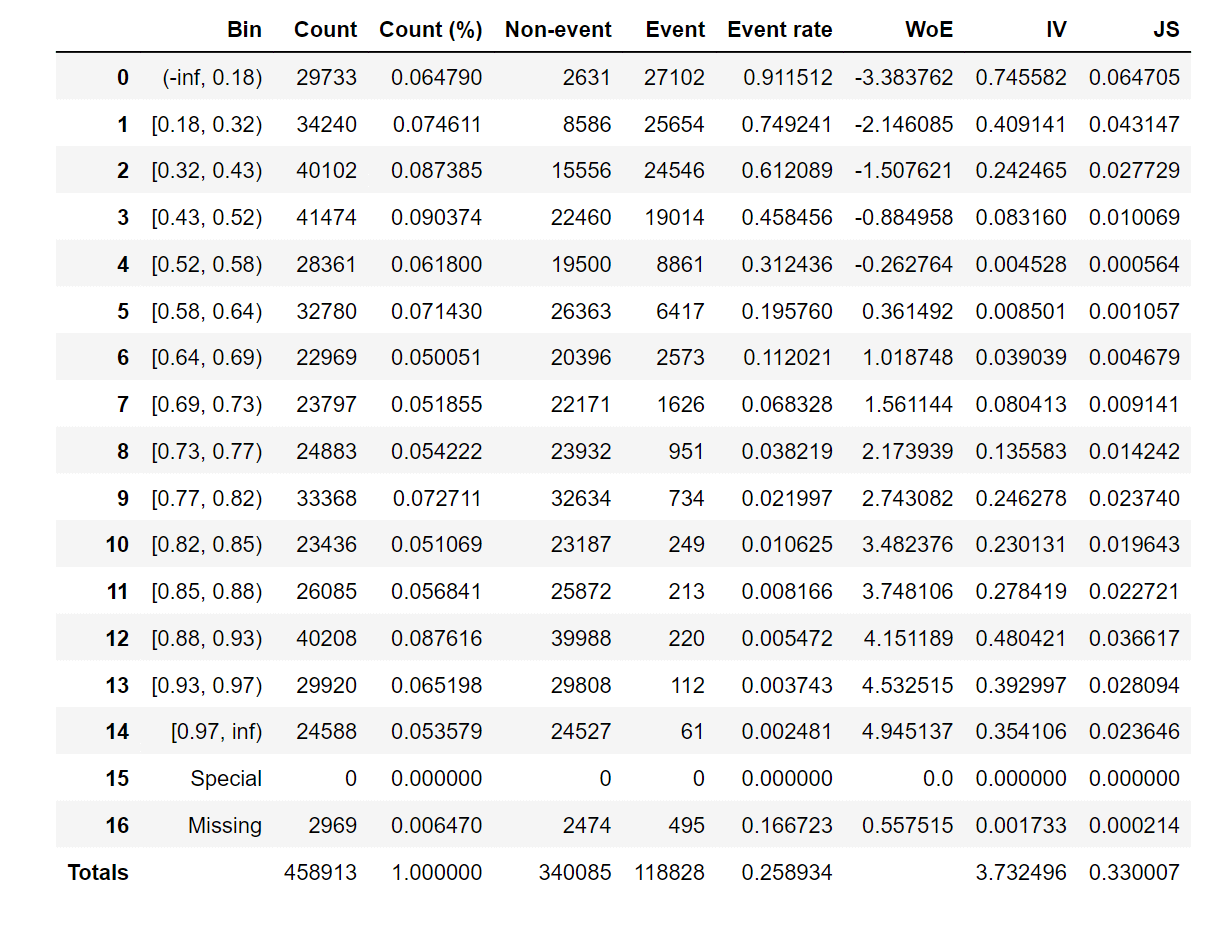
Output: 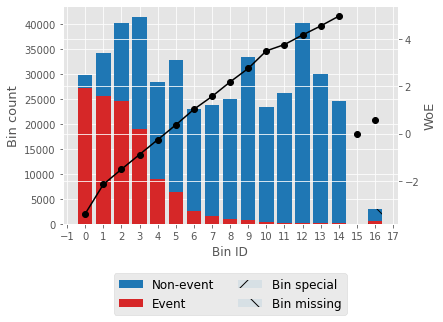
Output: 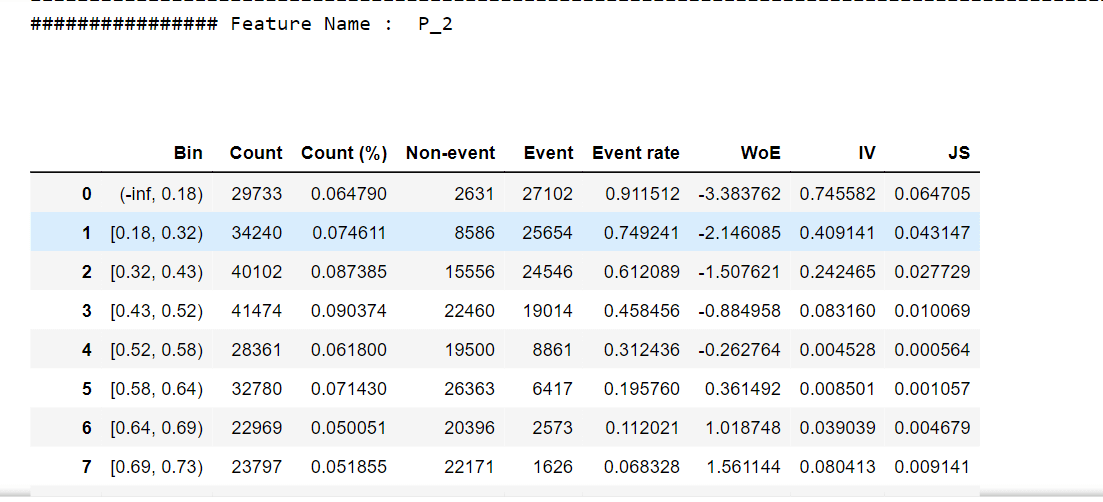 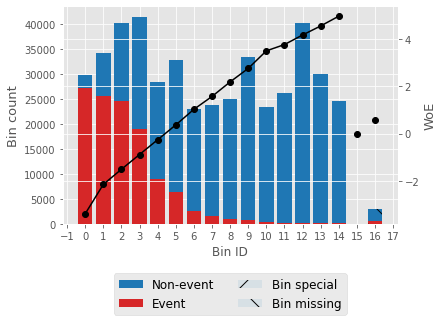 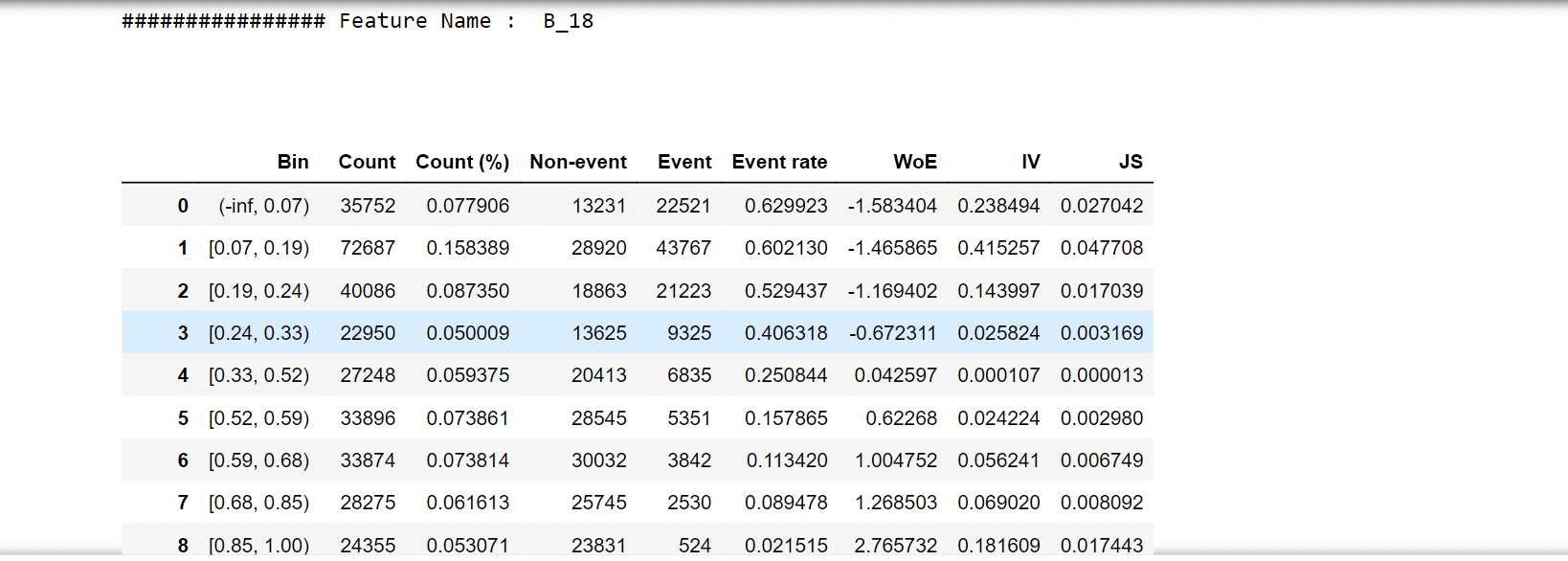 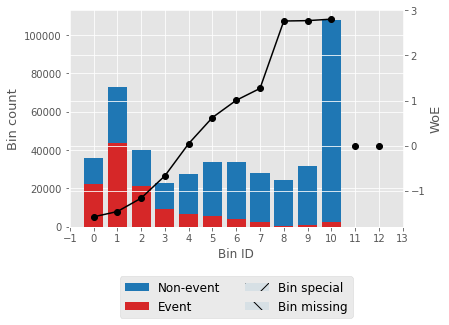 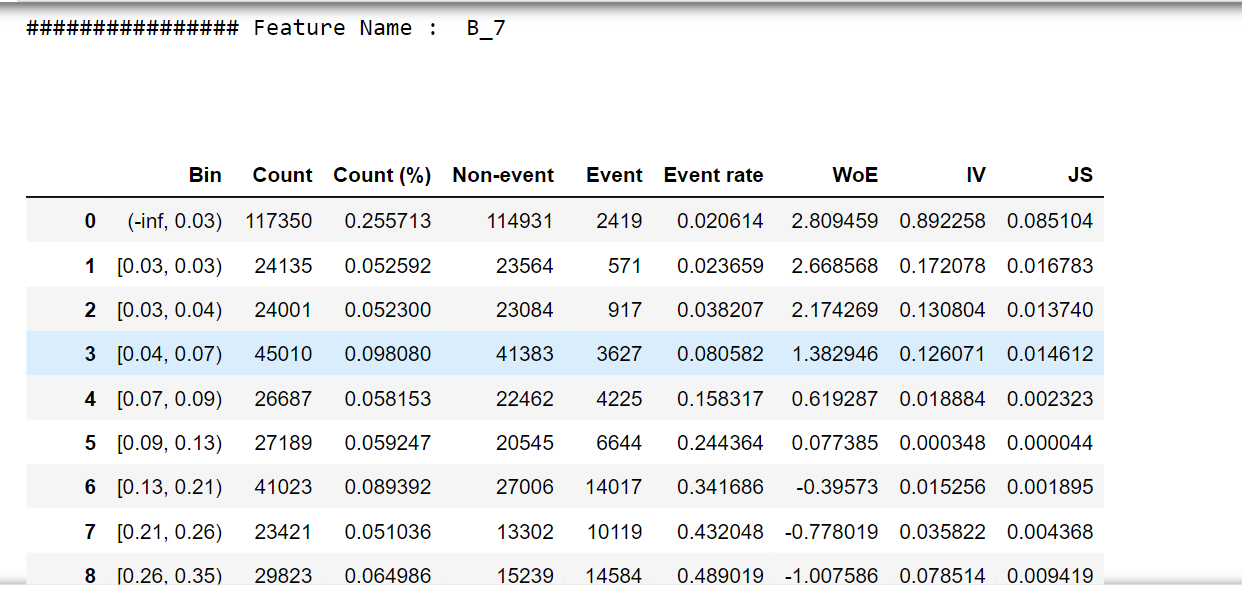 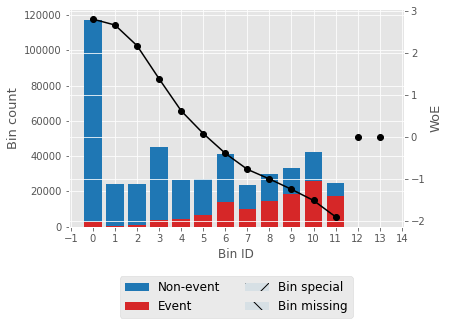 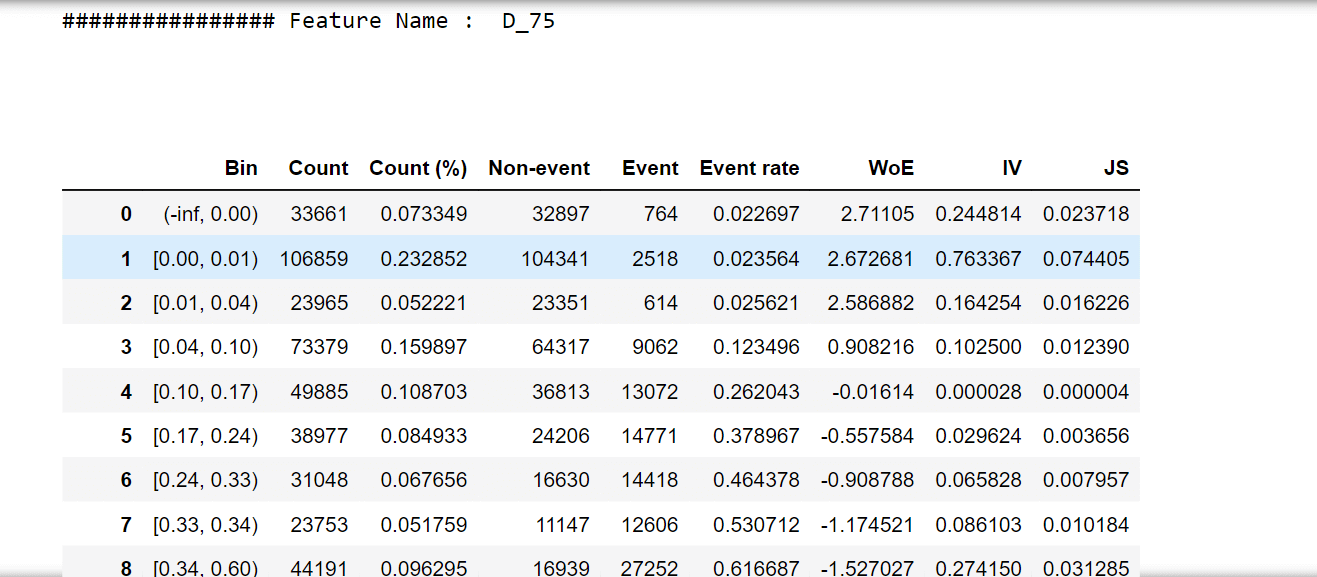 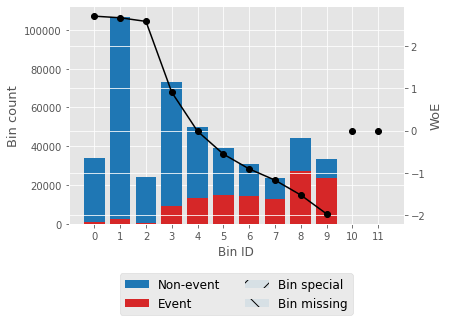 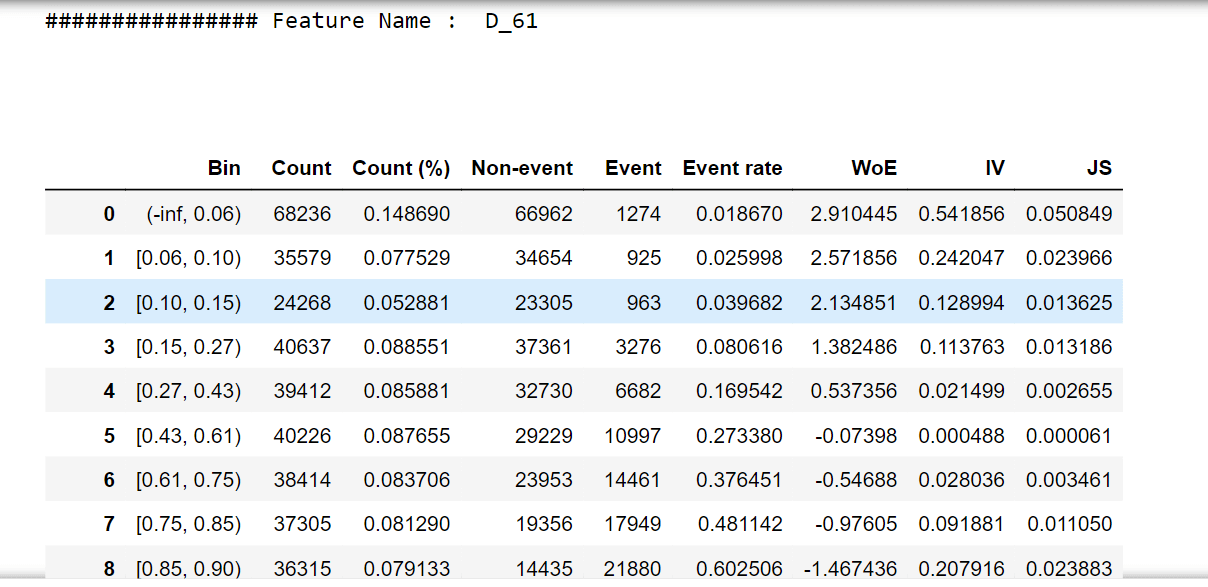 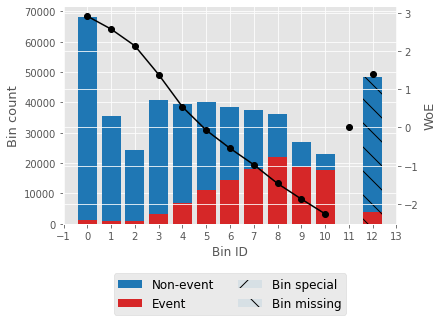 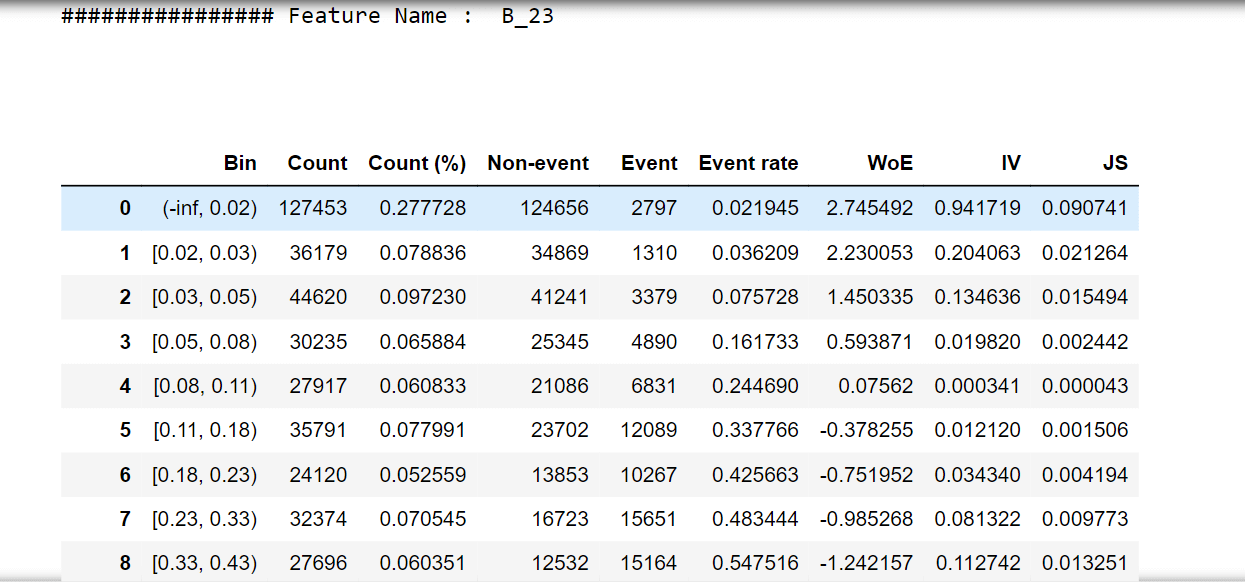 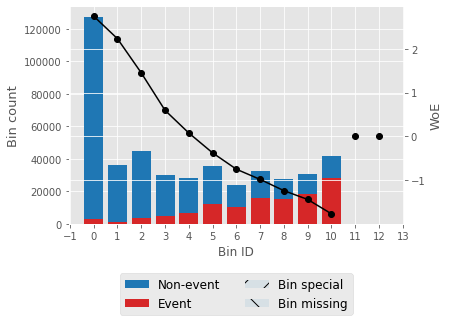 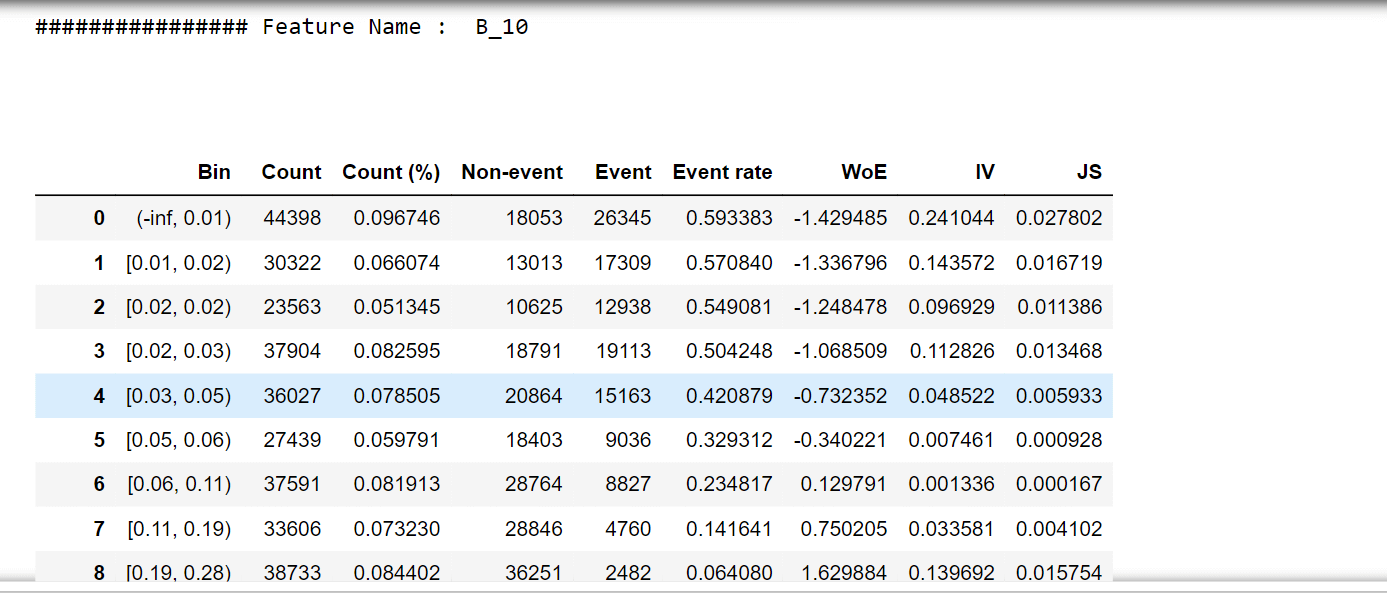 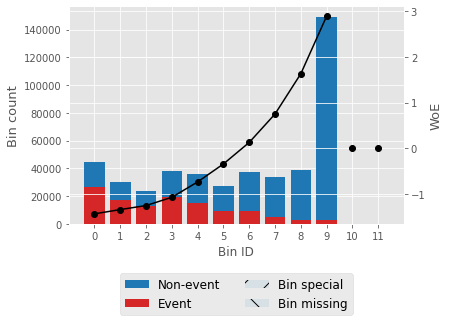 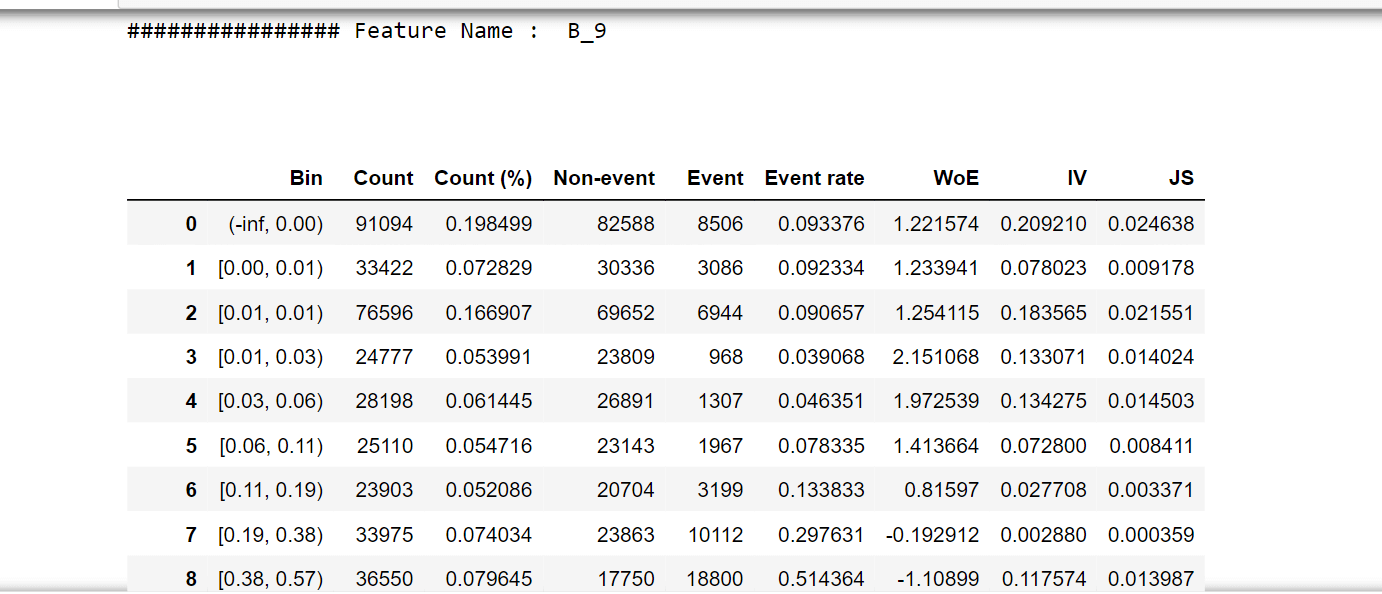 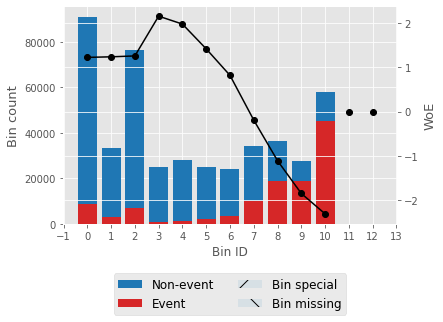 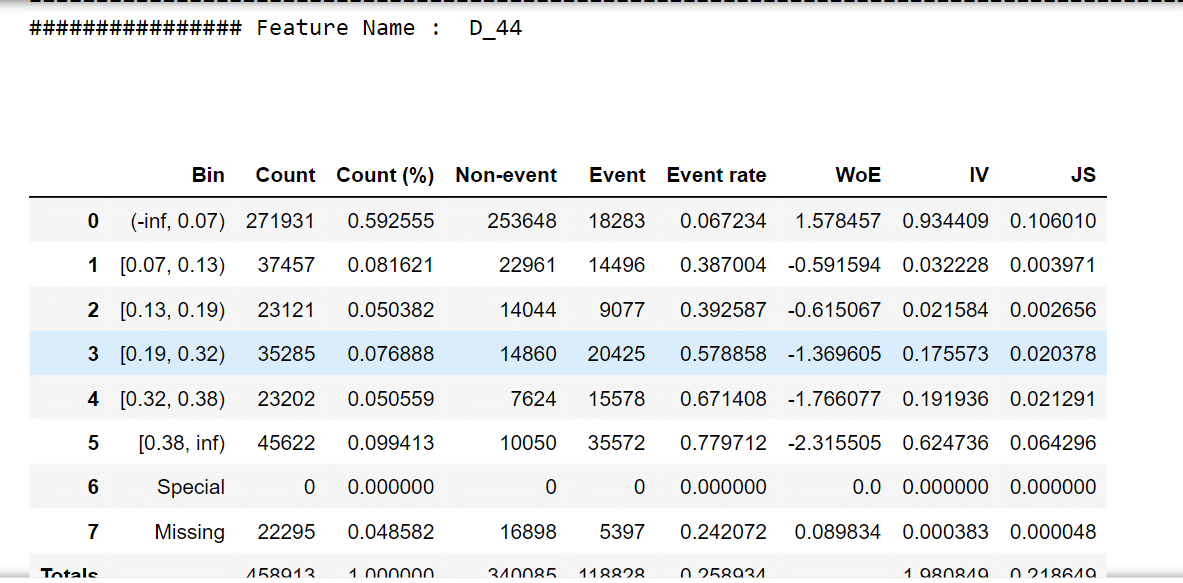 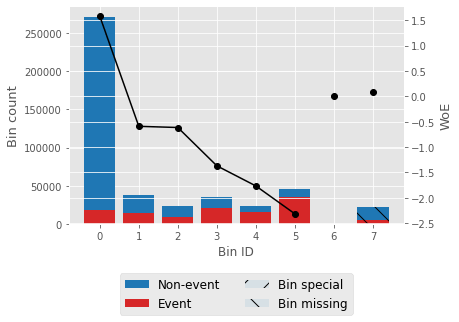 Selecting features that have IV values > 0.5. Correlation HeapOutput: 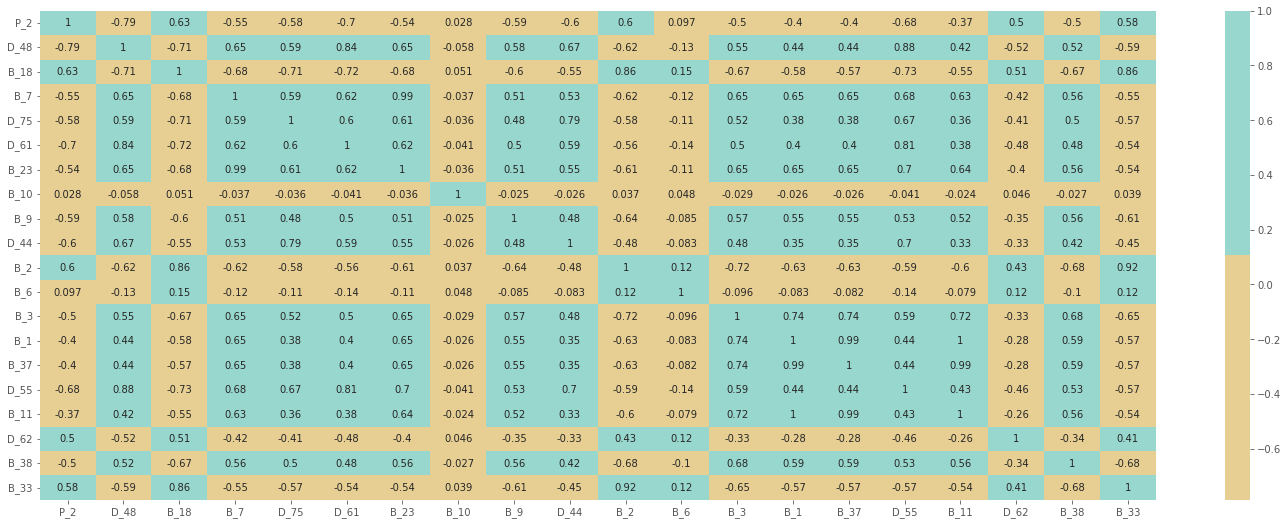 Output: 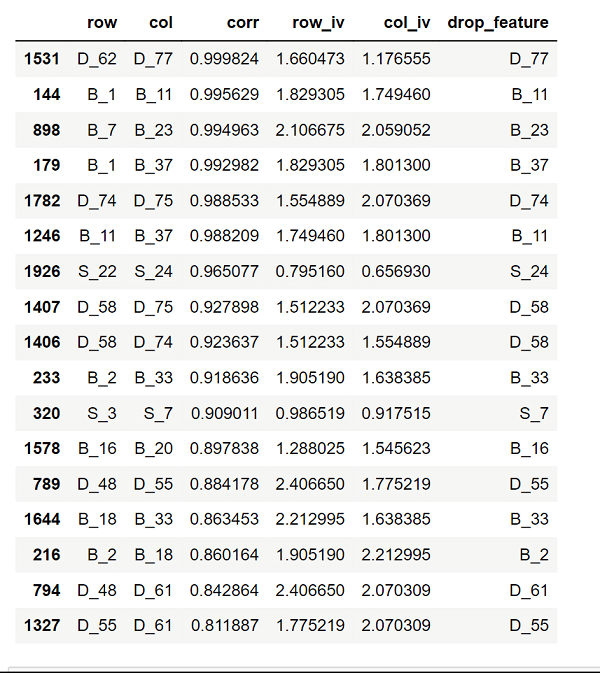
Output:  Output:  Output:  Output: 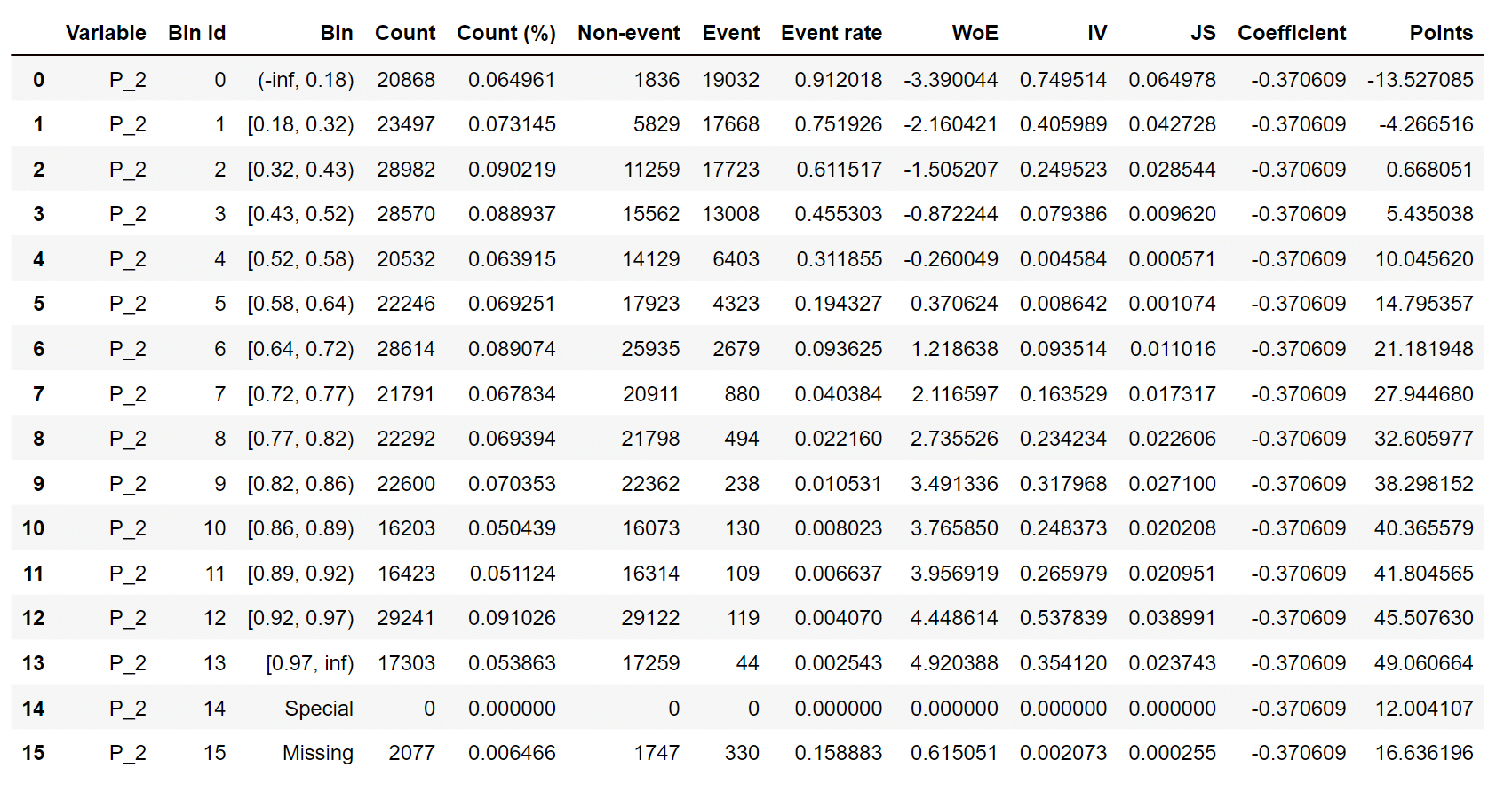
Output:  We have got a accuracy of 75 percent. Output:  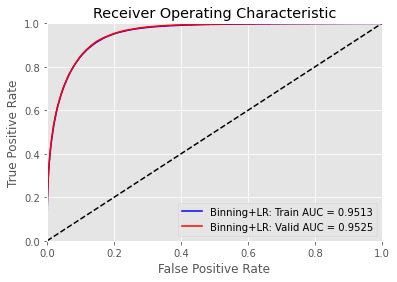 Output: 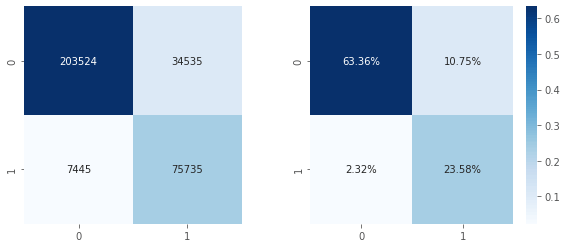 Output: 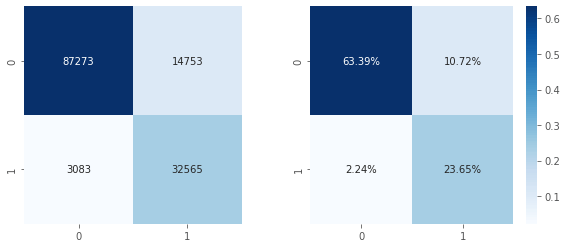 Output: 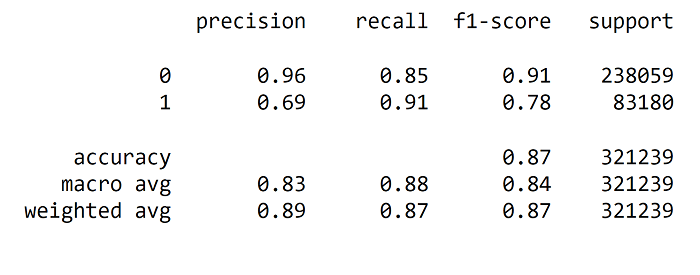 We have an accuracy of 87% Output: 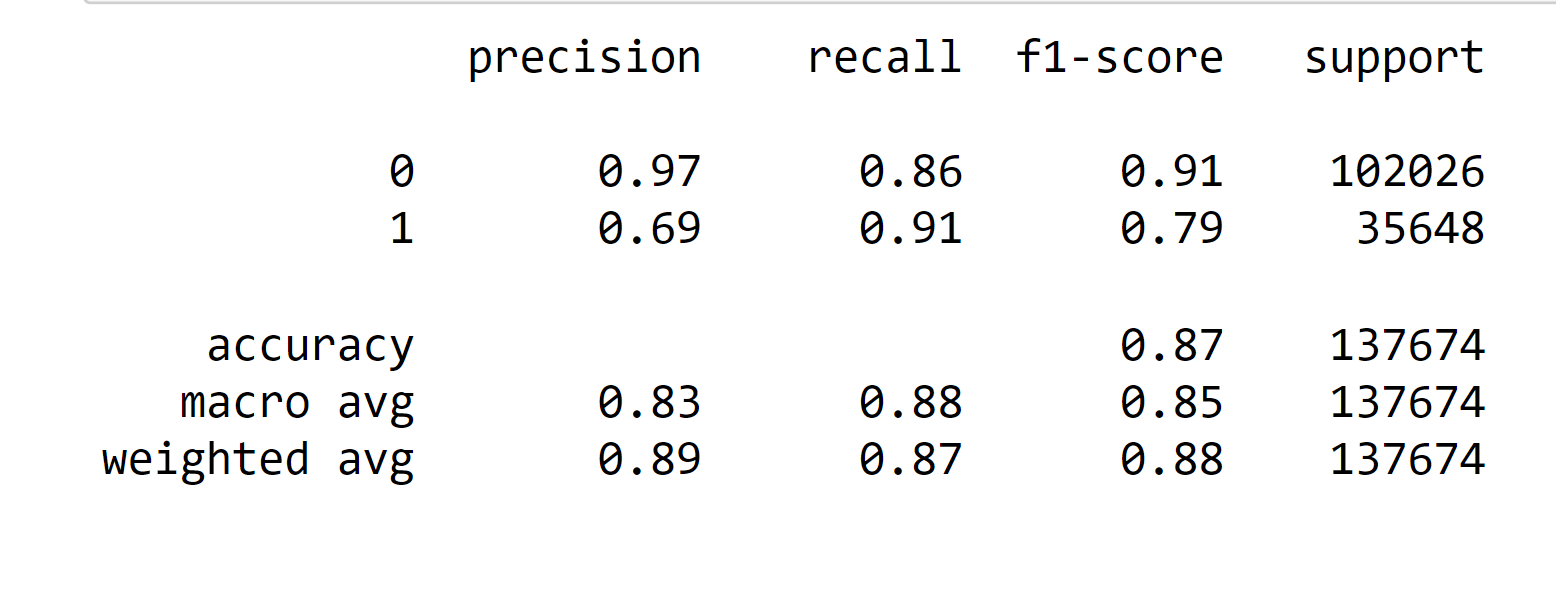
Output: 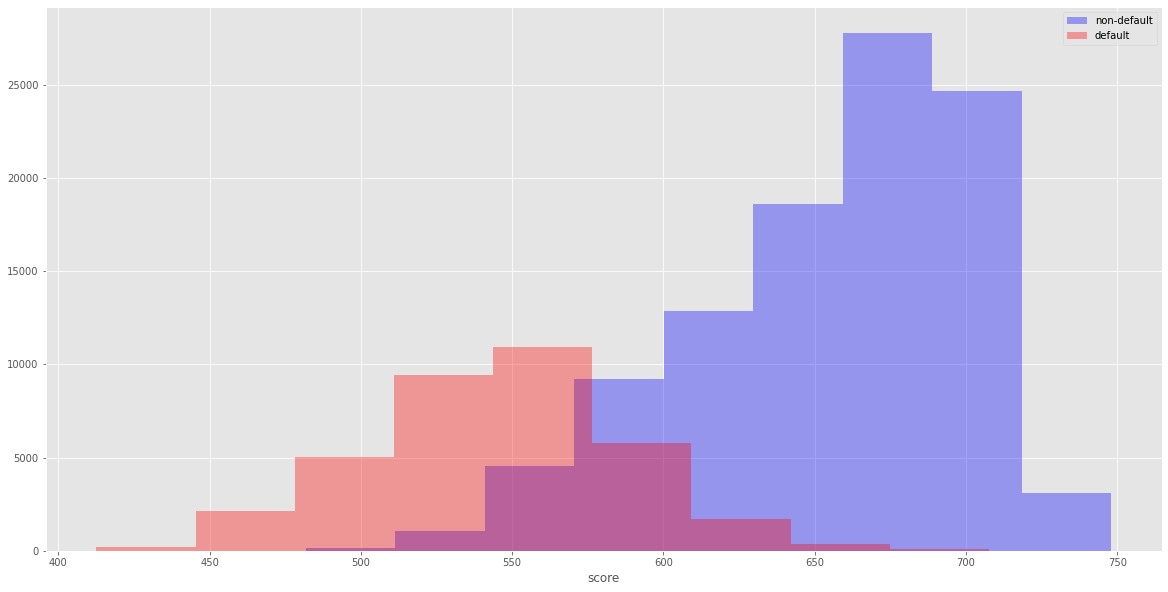
Output: 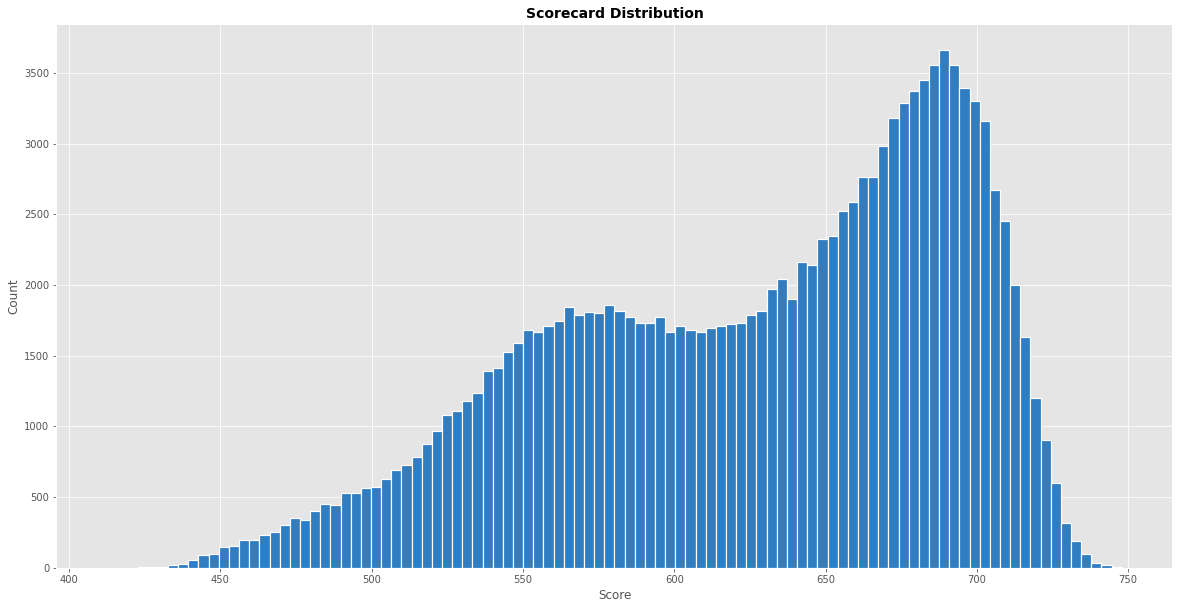 We can see that a lot of scorecards are in the range of 650-750. Output: 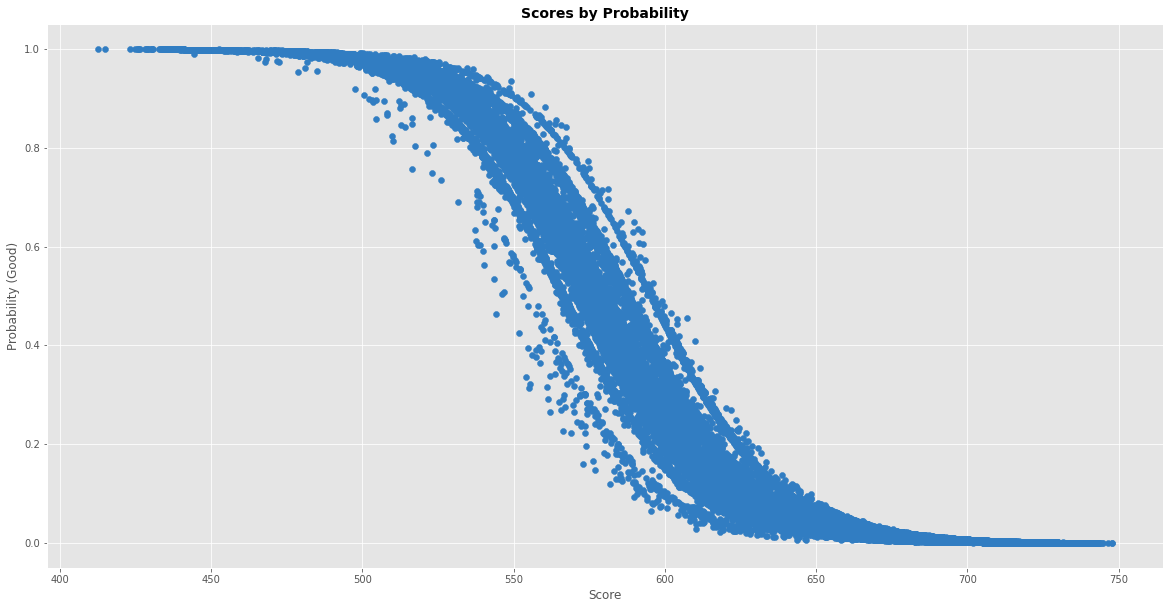 ConclusionMachine learning algorithms have revolutionized the credit scoring process by providing more accurate and efficient credit scoring decisions. They are able to analyze vast amounts of data and identify patterns to make more accurate predictions. However, there are challenges to consider, such as the complexity of machine learning models and the need for large amounts of high-quality data. Privacy is also a concern, and lenders must take steps to ensure that borrower data is protected and secure. Despite these challenges, the benefits of machine learning in credit scoring are clear, and it is likely that machine learning will continue to play an increasingly important role in credit scoring in the future. Next TopicExtrapolation in Machine Learning |
We provides tutorials and interview questions of all technology like java tutorial, android, java frameworks
G-13, 2nd Floor, Sec-3, Noida, UP, 201301, India






































