| |

Huffman Coding JavaThe Huffman Coding Algorithm was proposed by David A. Huffman in 1950. It is a lossless data compression mechanism. It is also known as data compression encoding. It is widely used in image (JPEG or JPG) compression. In this section, we will discuss the Huffman encoding and decoding, and also implement its algorithm in a Java program. We know that each character is a sequence of 0's and 1's and stores using 8-bits. The mechanism is called fixed-length encoding because each character uses the same number of fixed-bit storage. Here, a question ascends, is it possible to reduce the amount of space required to store a character? Yes, it is possible by using variable-length encoding. In this mechanism, we exploit some characters that occur more frequently in comparison to other characters. In this encoding technique, we can represent the same piece of text or string by reducing the number of bits. Huffman EncodingHuffman encoding implements the following steps.
Huffman coding follows a prefix rule that prevents ambiguity while decoding. The rule also ensures that the code assigned to the character is not treated as a prefix of the code assigned to any other character. There are the following two major steps involved in Huffman coding:
Let's brief the above two steps. Huffman TreeStep 1: For each character of the node, create a leaf node. The leaf node of a character contains the frequency of that character. Step 2: Set all the nodes in sorted order according to their frequency. Step 3: There may exist a condition in which two nodes may have the same frequency. In such a case, do the following:
Step 4: Repeat step 2 and 3 until all the node forms a single tree. Thus, we get a Huffman tree. Huffman Encoding ExampleSuppose, we have to encode string abracadabra. Determine the following:
(i) Huffman Code for All the CharactersIn order to determine the code for each character, first, we construct a Huffman tree. Step 1: Make pairs of characters and their frequencies. (a, 5), (b, 2), (c, 1), (d, 1), (r, 2) Step 2: Sort pairs with respect to frequency, we get: (c, 1), (d, 1), (b, 2) (r, 2), (a, 5) Step 3: Pick the first two characters and join them under a parent node. 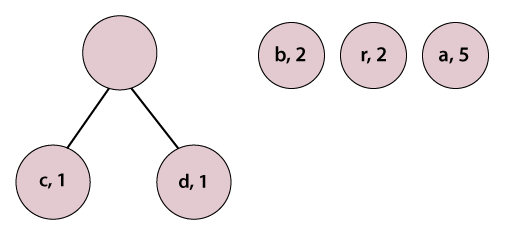
We observe that a parent node does not have a frequency so, we must assign a frequency to it. The parent node frequency will be the sum of its child nodes (left and right) i.e. 1+1=2. 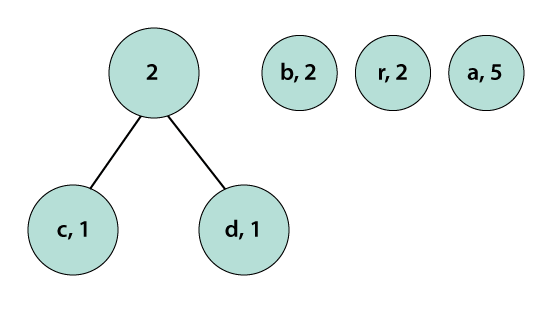
Step 4: Repeat Steps 2 and 3 until, we get a single tree. We observe that the pairs are already in a sorted (by step 2) manner. Again, pick the first two pairs and join them. 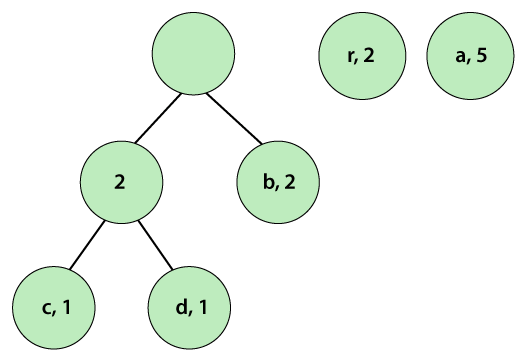
We observe that a parent node does not has a frequency so, we must assign a frequency to it. The parent node frequency will be the sum of its child nodes (left and right) i.e. 2+2=4. 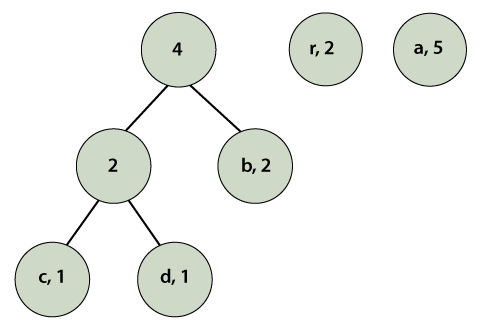
Again, we check if the pairs are in a sorted manner or not. At this step, we need to sort the pairs. 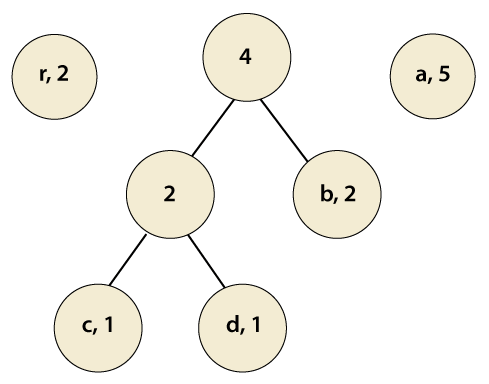
According to step 3, pick the first two pairs and join them, we get: 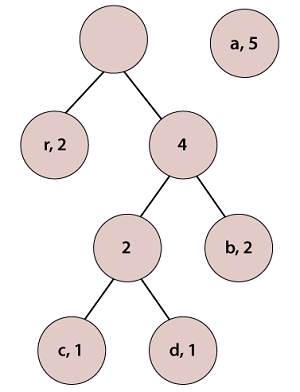
We observe that a parent node does not have a frequency so, we must assign a frequency to it. The parent node frequency will be the sum of its child nodes (left and right) i.e. 2+4=6. 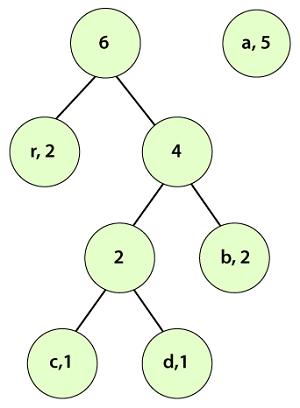
Again, we check if the pairs are in a sorted manner or not. At this step, we need to sort the pairs. After sorting the tree looks like the following: 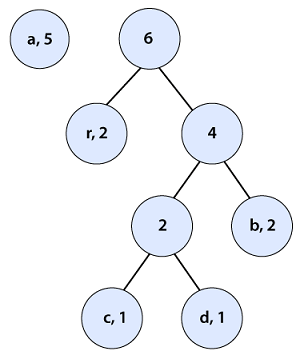
According to step 3, pick the first two pairs and join them, we get: 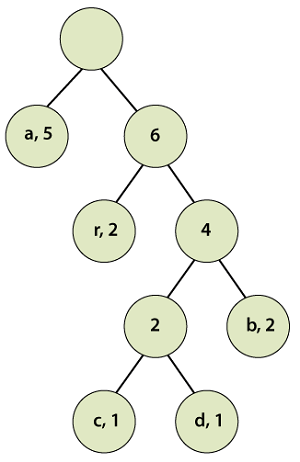
We observe that a parent node does not have a frequency so, we must assign a frequency to it. The parent node frequency will be the sum of its child nodes (left and right) i.e. 5+6=11. 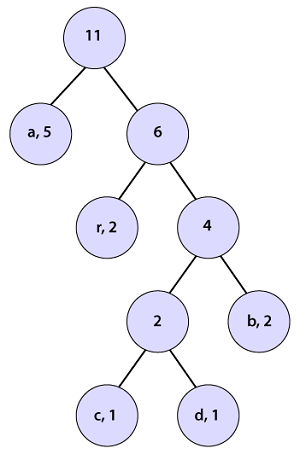
Therefore, we get a single tree. At last, we will find the code for each character with the help of the above tree. Assign a weight to each edge. Note that each left edge-weighted is 0 and the right edge-weighted is 1. 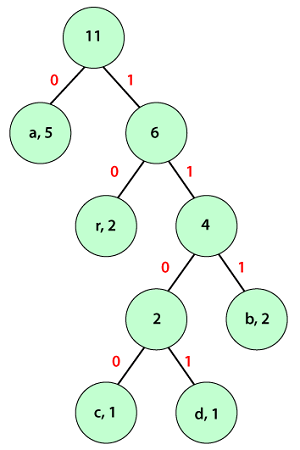
We observe that input characters are only presented in the leave nodes and the internal nodes have null values. In order to find the Huffman code for each character, traverse over the Huffman tree from the root node to the leaf node of that particular character for which we want to find code. The table describes the code and code length for each character.
We observe that the most frequent character gets the shortest code length and the less frequent character gets the largest code length. Now we can encode the string (abracadabra) that we have taken above. (ii) Average Code Length for the StringThe average code length of the Huffman tree can be determined by using the formula given below: = { (5 x 1) + (2 x 3) + (1 x 4) + (1 x 4) + (2 x 2) } / (5+2+1+1+2) = 2.09090909 (iii) Length of the Encoded StringThe length of the encoded message can be determined by using the following formula: = 11 x 2.09090909 = 23 bits Huffman Encoding AlgorithmThe Huffman algorithm is a greedy algorithm. Since at every stage the algorithm looks for the best available options. The time complexity of the Huffman encoding is O(nlogn). Where n is the number of characters in the given text. Huffman DecodingHuffman decoding is a technique that converts the encoded data into initial data. As we have seen in encoding, the Huffman tree is made for an input string and the characters are decoded based on their position in the tree. The decoding process is as follows:
The child node holds the input character. It is assigned the code formed by subsequent 0s and 1s. The time complexity of decoding a string is O(n), where n is the length of the string. Huffman Encoding and Decoding Java ProgramIn the following program, we have used data structures like priority queues, stacks, and trees to design a compression and decompression logic. We will base our utilities on the widely used algorithmic technique of Huffman coding. HuffmanCode.java Output:
Huffman Codes of the characters are: {p=000, a=110, t=111, v=001, i=010, j=011, n=100, o=101}
The initial string is: javatpoint
The encoded string is: 011110001110111000101010100111
The decoded string is: javatpoint
Next TopicJava Snippet Class
|
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








