Recommendation System - Machine LearningA machine learning algorithm known as a recommendation system combines information about users and products to forecast a user's potential interests. These systems are used in a wide range of applications, such as e-commerce, social media, and entertainment, to provide personalized recommendations to users. There are several types of recommendation systems, including:
The choice of which type of recommendation system to use depends on the specific application and the type of data available. It's worth noting that recommendation systems are widely used and can have a significant impact on businesses and users. However, it's important to consider ethical considerations and biases that may be introduced to the system. In this article, We utilize a dataset from Kaggle Datasets: Articles Sharing and Reading from CI&T Deskdrop in this project. For the purpose of giving customers individualized suggestions, we will demonstrate how to develop Collaborative Filtering, Content-Based Filtering, and Hybrid techniques in Python. Details About DatasetThe Deskdrop dataset from CI&T's Internal Communication platform, which is an actual sample of 12 months' worth of logs (from March 2016 to February 2017). (DeskDrop). On more than 3k publicly published articles, there are around 73k documented user interactions. Two CSV files make up the file:
Now, we will try to implement it in the code. Importing LibrariesLoading the DatasetHere, we have to load our dataset to perform the machine learning operations. As we already know that we have two CSV files as the dataset. 1. shared_articles.csvIt includes data on the articles posted on the platform. Each article contains a timestamp for when it was shared, the original url, the title, plain text content, the language it was shared in (Portuguese: pt or English: en), and information about the individual who shared it (author).
We will just analyze the "CONTENT SHARED" event type here for the purpose of simplicity, making the erroneous assumption that all articles were accessible for the whole one-year period. Only publications that were available at a specific time should be recommended for a more accurate review, but we'll do this exercise for you anyhow. Output: 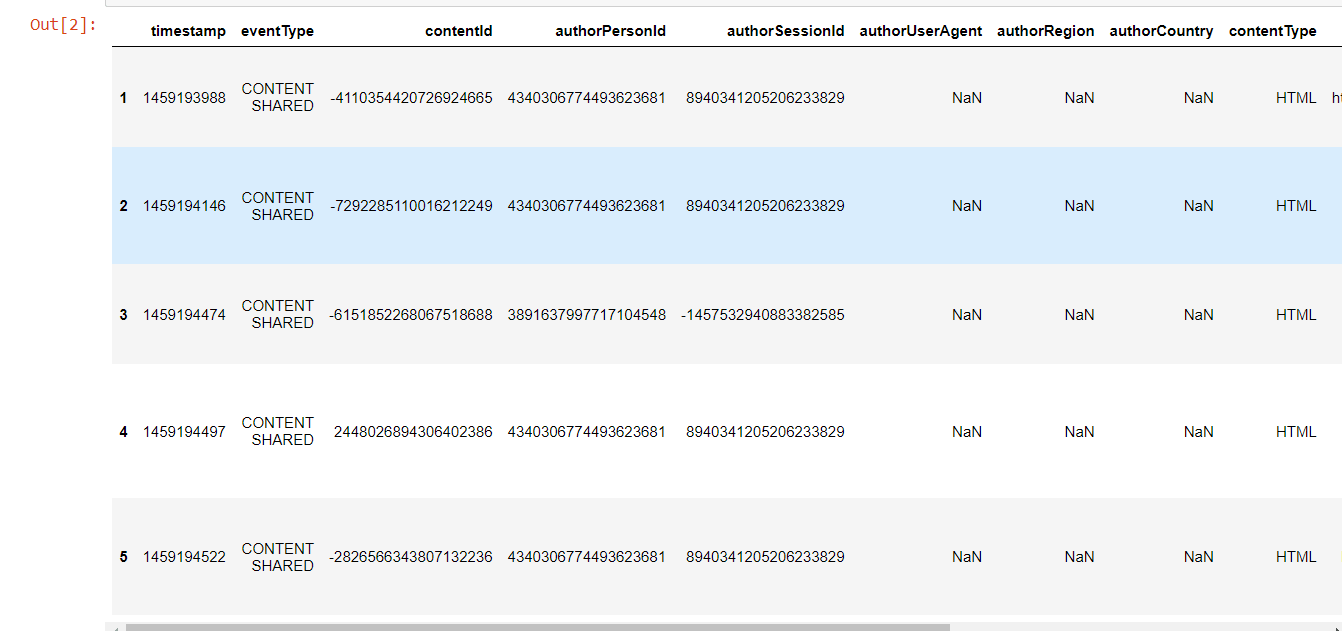 2. users_interactions.csvIt includes user interaction records for shared content. By using the contentId field, it may be connected to articles shared.csv. The values for eventType are:
Output: 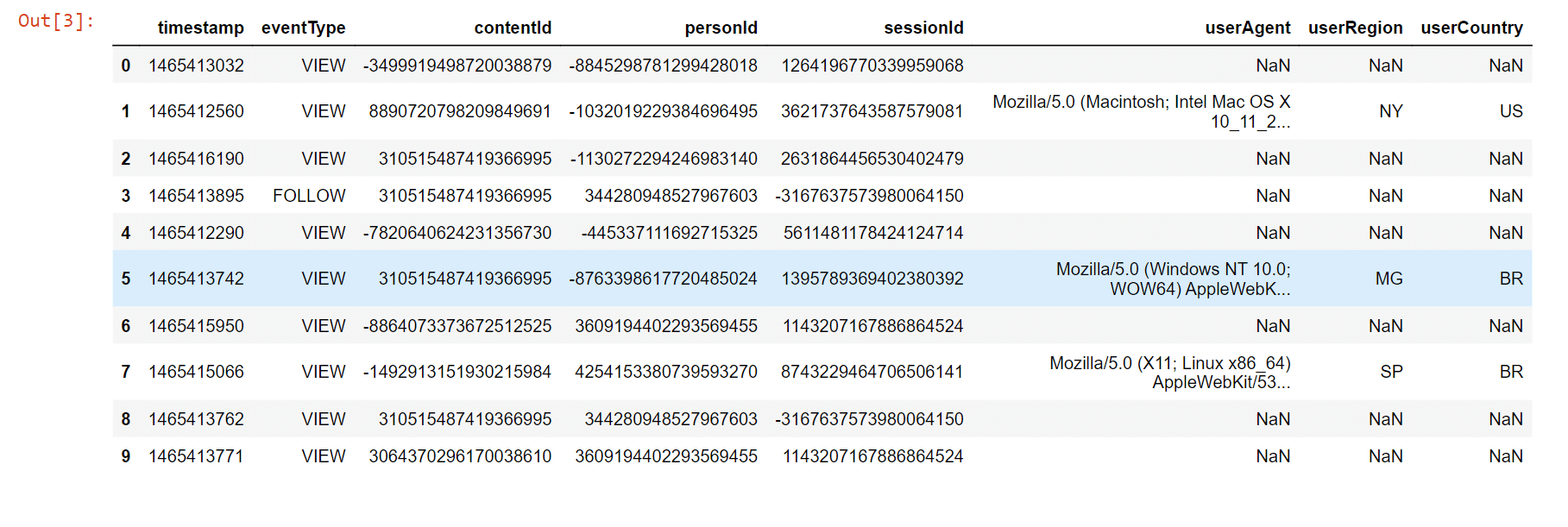 Data ManipulationHere, we assign a weight or strength to each sort of interaction since there are many kinds. For instance, we believe that a remark in an article indicates a user's interest in the item is more significant than a like or a simple view. Note: User cold-start is a problem with recommender systems that makes it difficult to give consumers with little or no consumption history individualized recommendations since there isn't enough data to model their preferences.Due to this, we are only retaining users in the dataset who had at least five interactions. Output:  Output:  Desk drop allows users to browse articles several times and engage with them in various ways (e.g. like or comment). We thus combine all of the interactions a user had with an item by a weighted total of interaction type strength, and then apply a log transformation to smooth the distribution and utilize this information to model the user interest in a particular article. Output: 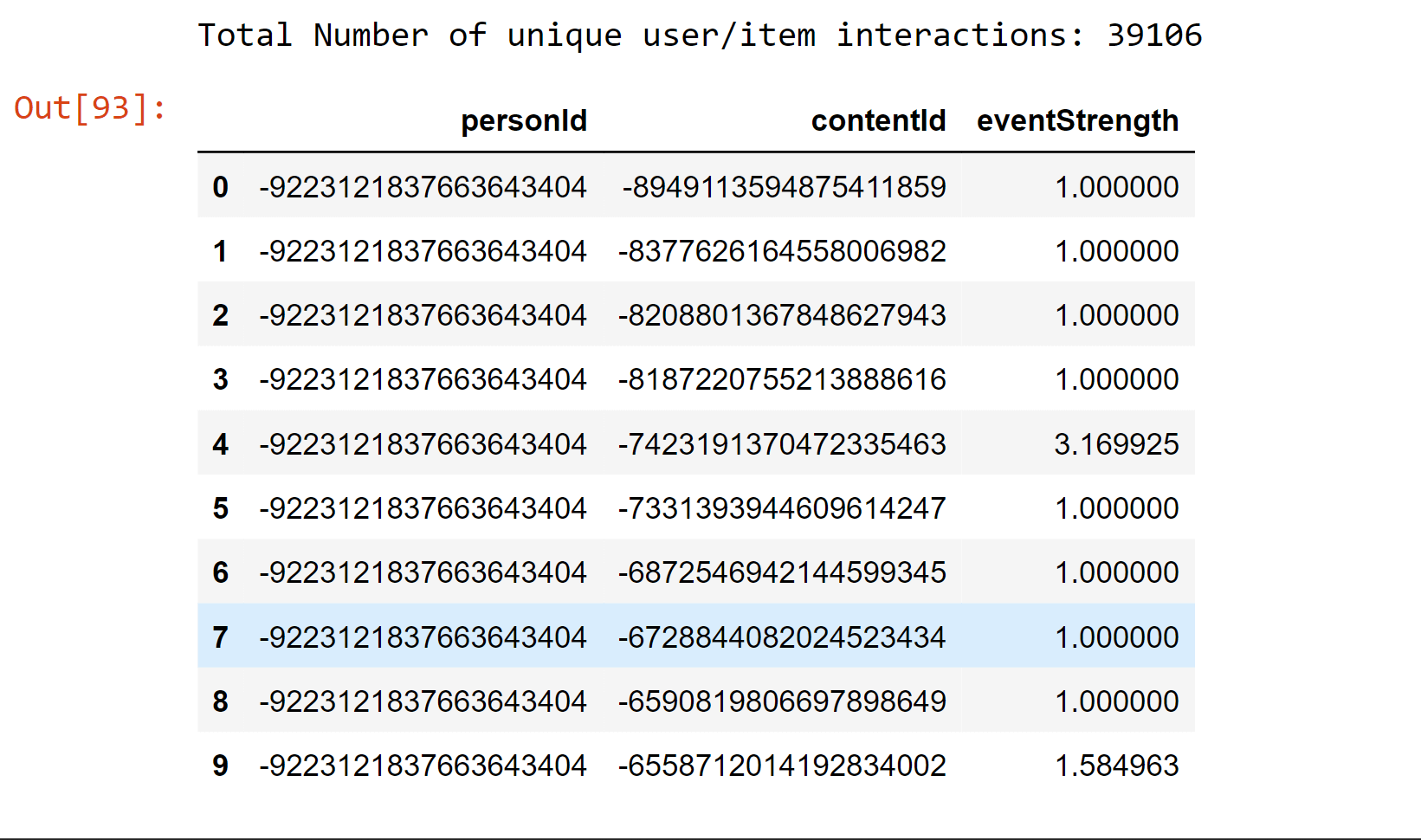 EvaluationEvaluation is crucial for machine learning projects because it enables objective comparison of various methods and model hyperparameter selections. Making sure the trained model generalizes for data it was not trained on utilizing cross-validation procedures is a crucial component of assessment. Here, we employ a straightforward cross-validation technique known as a holdout, in which a random data sample?in this case, 20%?is set aside throughout training and utilized just for assessment. This article's assessment metrics were all calculated using the test set. A more reliable assessment strategy would involve dividing the train and test sets according to a reference date, with the train set being made up of all interactions occurring before that date and the test set consisting of interactions occurring after that day. For the sake of simplicity, we decided to utilize the first random strategy for this notebook, but you might want to try the second way to more accurately replicate how the recsys would behave in production when anticipating interactions from "future" users. Output:  There are a number of metrics that are frequently used for assessment in recommender systems. We decided to employ Top-N accuracy measures, which assess the precision of the top suggestions made to a user in comparison to the test set items with which the user has actually interacted. According to how this assessment process operates:
Recall@N, which assesses if the interacted item is one of the top N items (hit) in the prioritized list of 101 suggestions for a user, was chosen as the Top-N accuracy metric. NDCG@N and MAP@N are two more well-liked ranking metrics whose computation of the score takes into consideration the position of the pertinent item in the ranked list (max. value if the relevant item is in the first position). Now we will create a class named "ModelEvaluator", as this will be used for the evaluation of the recommendation model that we will create. Popularity ModelThe Popularity model is a typical baseline strategy that is typically challenging to surpass. This strategy merely suggests to a user the most well-liked products that the customer has not yet eaten; it is not personally tailored. As the "wisdom of the multitude" is accounted for by popularity, it typically offers sound advice that is generally engaging for most people. A recommender system's main goal, which goes much beyond this straightforward method, is to apply long-tail products to users with extremely particular interests. Output: 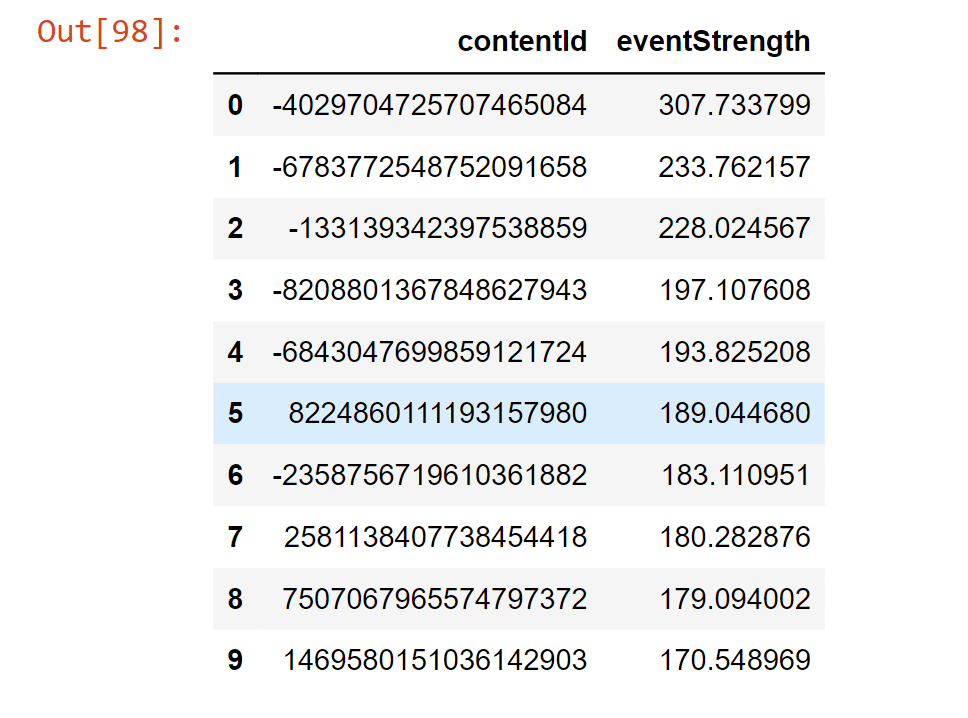 Here, using the above-described methodology, we evaluate the Popularity model. It had a Recall@5 of 0.2417, which suggests that the Popularity model placed around 24% of the test set's interactive items among the top 5 items (from lists with 100 random items). Furthermore, as predicted, Recall@10 was significantly higher (37%) You might find it surprising that popular models can typically perform so well. Output: 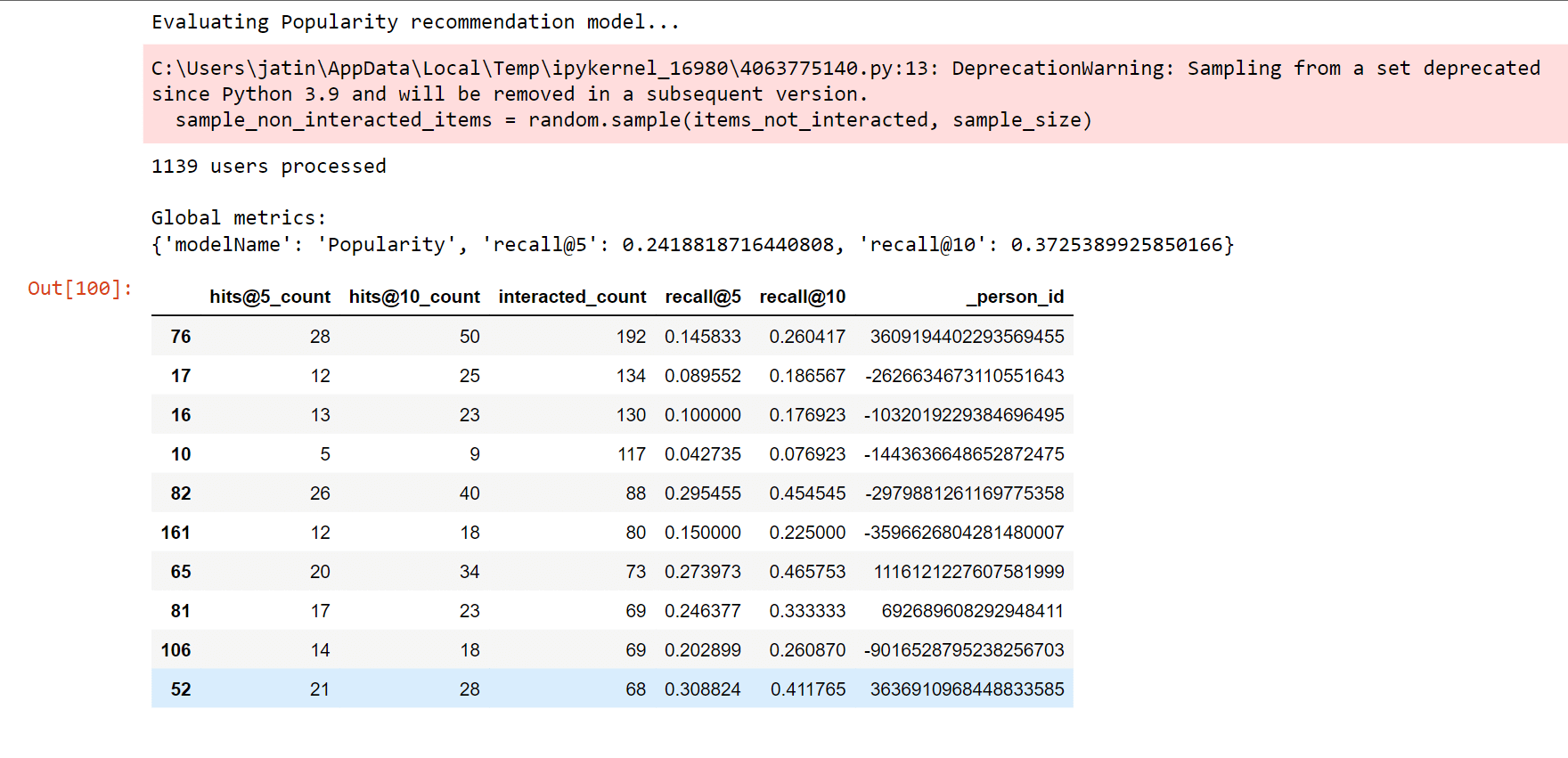 Content-Based Filtering modelThe descriptions or qualities of the objects with which the user has engaged are used in content-based filtering techniques to suggest related items. This solution is reliable in preventing the cold-start issue since it only relies on the user's prior decisions. It is straightforward to create item profiles and user profiles for text-based objects like books, articles, and news stories using the raw text. In this case, we're employing TF-IDF, a highly well-liked information retrieval (search engine) approach. Using this method, unstructured text is transformed into a vector structure, where each word is represented by a location in the vector, and the value indicates how pertinent a word is for an article. The same Vector Space Model will be used to represent all things, making it possible to compare articles. Output:  We average all the item profiles with which the user has engaged in order to model the user profile. The final user profile will give more weight to the articles on which the user has interacted the most (e.g., liked or commented), with the average being weighted by the strength of the interactions. Output:  Let's look at the profile first. It is a unit vector with a length of 5000. Each position's value indicates how vital a token (a bigram or a unigram) is to me. According to a look at below profile, the most pertinent tokens actually do reflect interests in machine learning, deep learning, artificial intelligence, and the Google Cloud Platform professionally! Therefore, we may anticipate some solid advice here! Output: 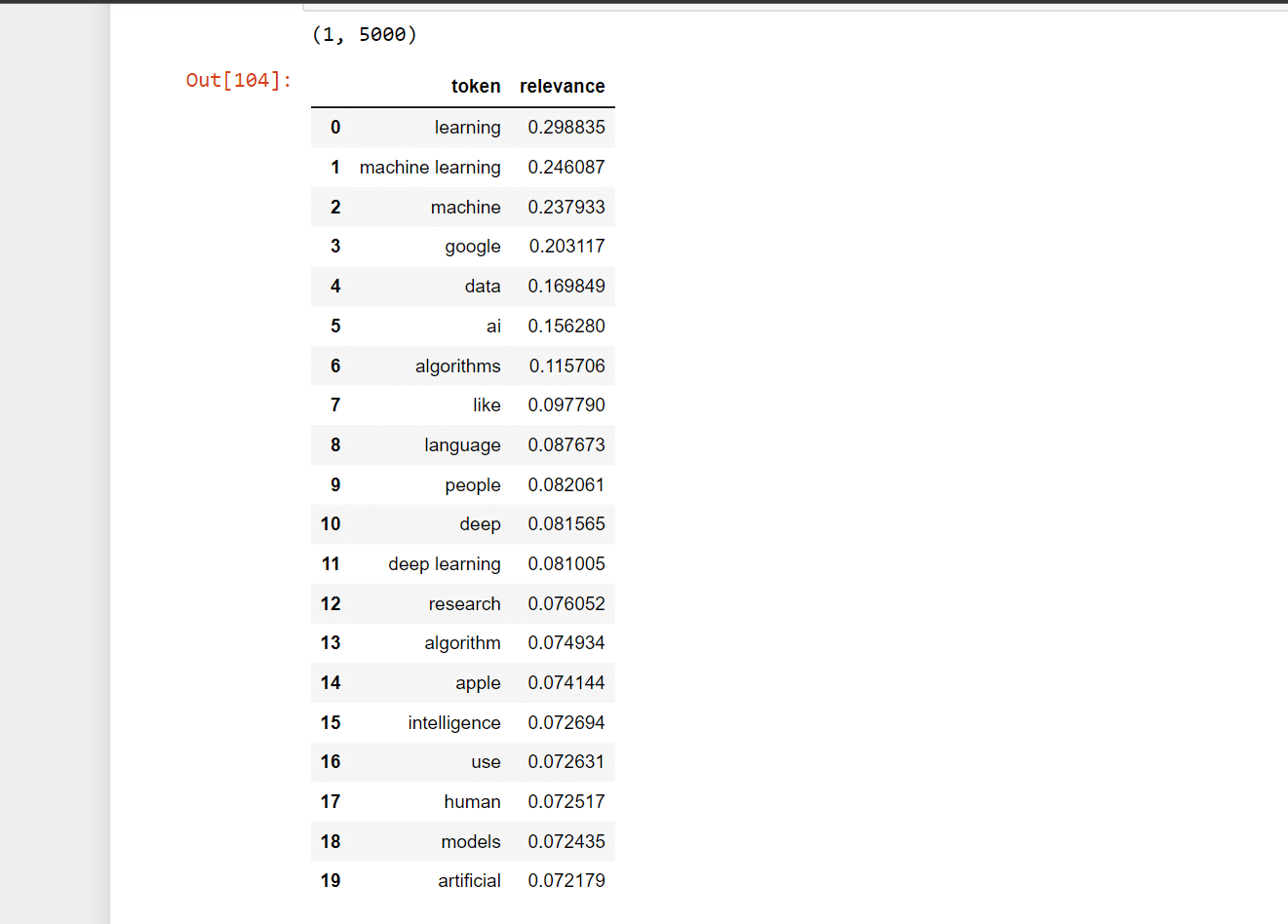 We have a Recall@5 of 0.162 with the customized recommendations of the content-based filtering model, which indicates that around 16% of the test set's interacting items were listed by this model among the top 5 things (from lists with 100 random items). Recall@10 was 0.261 (52%), as well. The fact that the Information-Based model performed less well than the Popularity model suggests that consumers may not be as committed to reading content that is highly similar to what they have already read. Output: 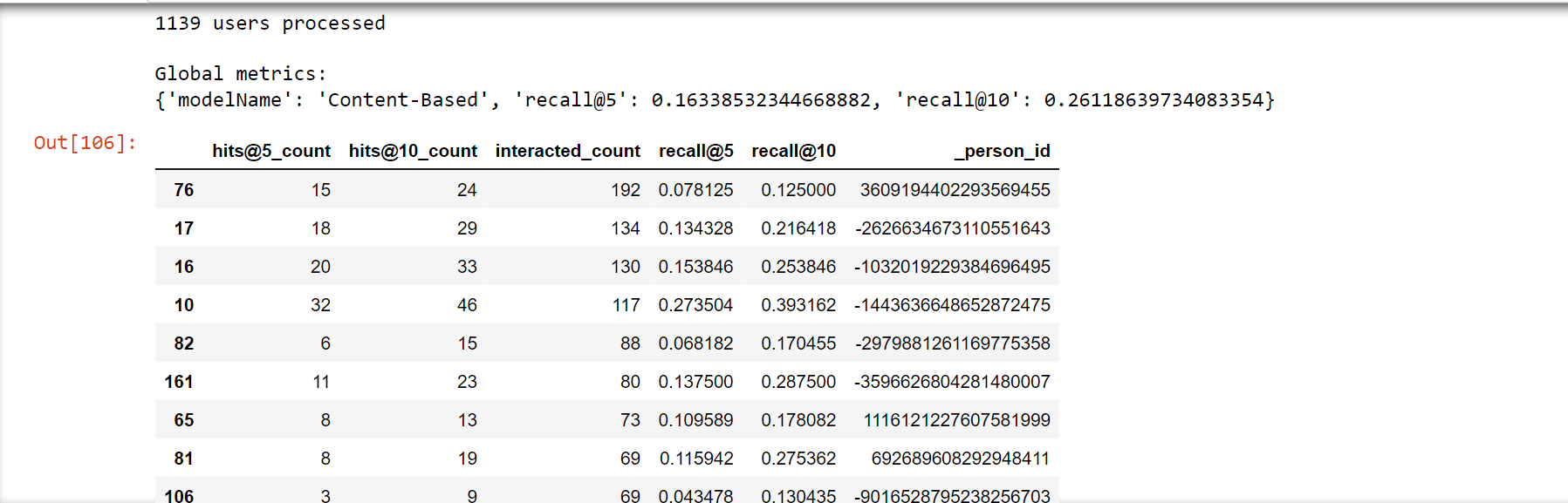 Collaborative Filtering modelIt has main implementation methods.
User Neighbourhood-based CF is a common illustration of this strategy, in which the top N similarly inclined users (typically determined using Pearson correlation) for a user are chosen and used to suggest products that those inclined users liked but with whom the current user has not yet interacted. Although this strategy is relatively easy to put into practice, it often does not scale effectively for numerous people. Crab offers an excellent Python implementation of this strategy.
Matrix FactorisationUser-item matrices are condensed into a low-dimensional form using latent component models. This method has the benefit of working with a much smaller matrix in a lower-dimensional space rather than a high-dimensional matrix with a large number of missing values. Both the user-based and item-based neighbourhood algorithms described in the preceding section might be used with a reduced presentation. This paradigm has a number of benefits. Compared to memory-based ones, it handles the sparsity of the original matrix better. Additionally, it is much easier to compare similarities in the generated matrix, especially when working with sizable sparse datasets. Here, we employ Singular Value Decomposition, a well-known latent component model (SVD). You might also use other, more CF-specific matrix factorization frameworks like surprise, mrec, or python-recsys. We choose a SciPy implementation of SVD since Kaggle kernels support it. The choice of how many elements to factor in the user-item matrix is crucial. The factorization in the original matrix reconstructions is more exact the more factors there are. As a result, if the model is permitted to retain too many specifics of the original matrix, it may struggle to generalize to data that was not used for training. The generality of the model is increased by reducing the number of components. Output:  Output:  Output:  Output:  Output:  Output:  Output:  We attempt to rebuild the original matrix by multiplying the elements after factorization. As a result, the matrix is no longer sparse. We will utilize the predictions for goods with which the user has not yet interacted to produce recommendations. Output:  Output:  Output:  Recall@5 (33%) and Recall@10 (46%) values were obtained while evaluating the Collaborative Filtering model (SVD matrix factorization), which is much higher than the Popularity model and Content-Based model. Output: 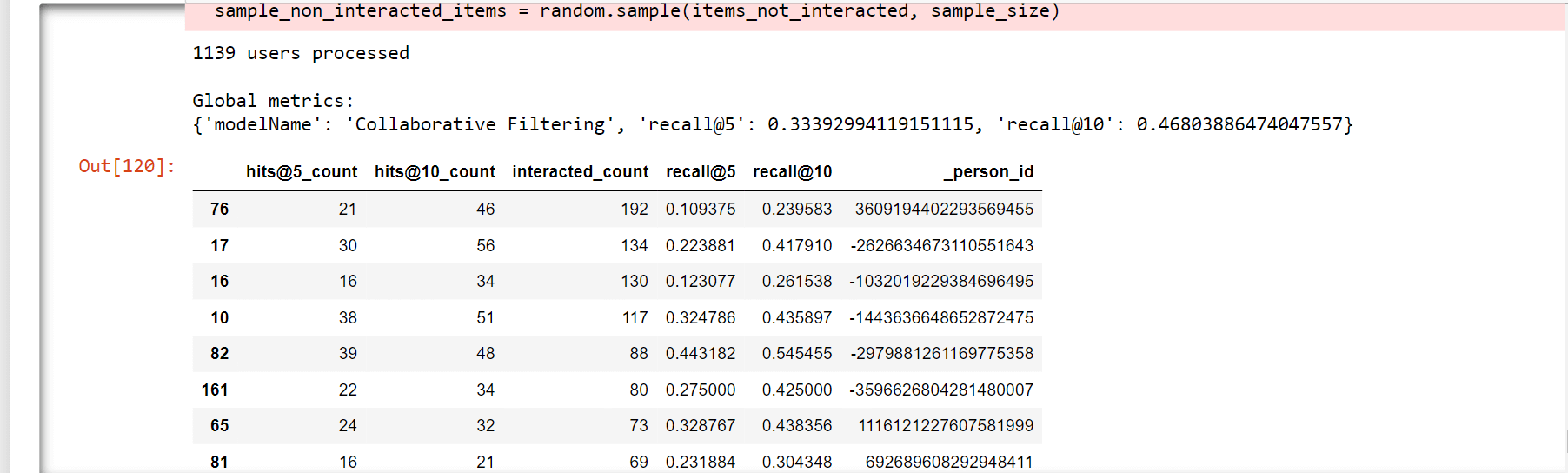 Hybrid RecommenderIt is a combination of Collaborative Filtering and Content-Based Filtering methods. In reality, several studies have shown that hybrid methods outperform individual approaches, and both academics and practitioners frequently adopt them. Let's create a straightforward hybridization technique that ranks items based on the weighted average of the normalized CF and Content-Based scores. The weights for the CF and CB models in this instance are 100.0 and 1.0, respectively, because the CF model is significantly more accurate than the CB model. Output: 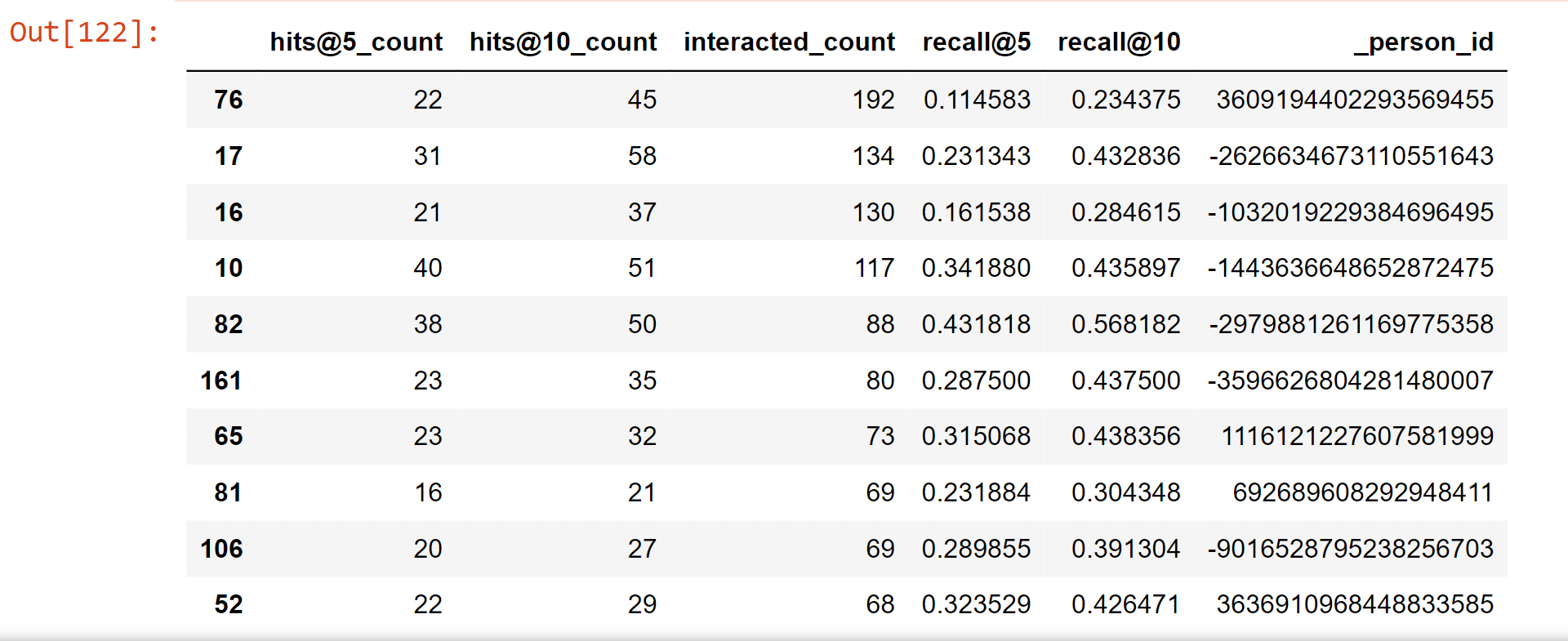 Comparing the MethodsNow, we will compare the methods for recall@5 and recall@10. Output: 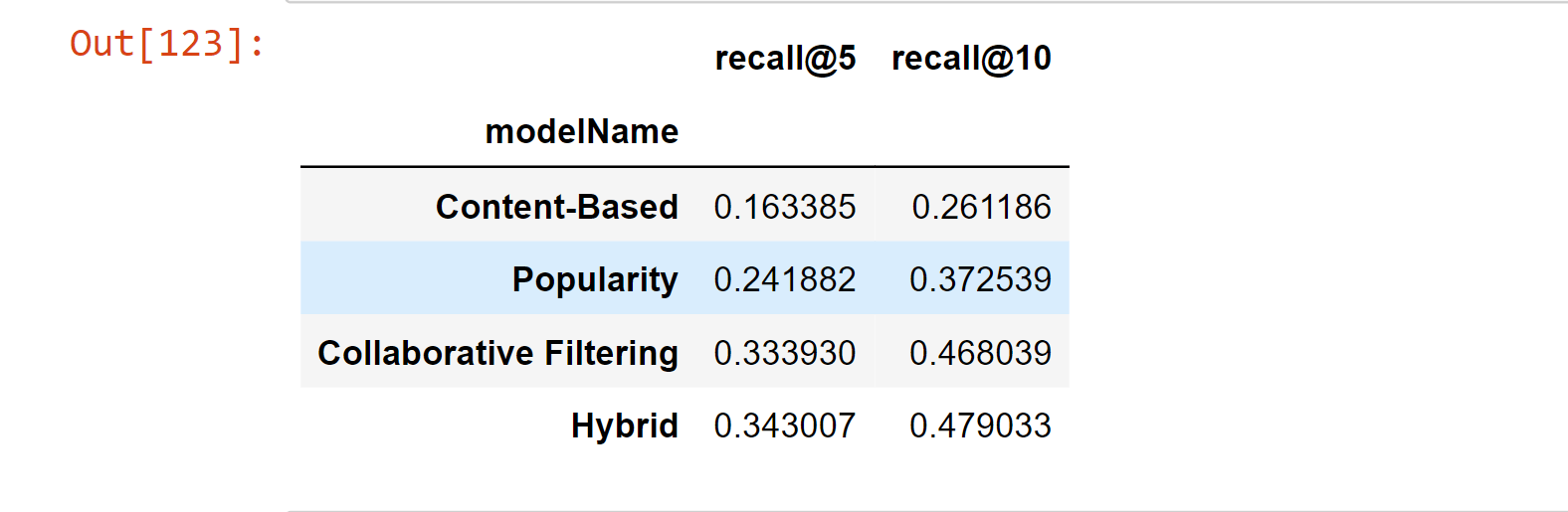 A new champion has emerged! By combining Collaborative Filtering and Content-Based Filtering, our straightforward hybrid technique outperforms the former. Recall@5 is currently 34.2%, while Recall@10 is 47.9%. Now for better understanding, we can also plot the graph for the comparison of the models. Output: 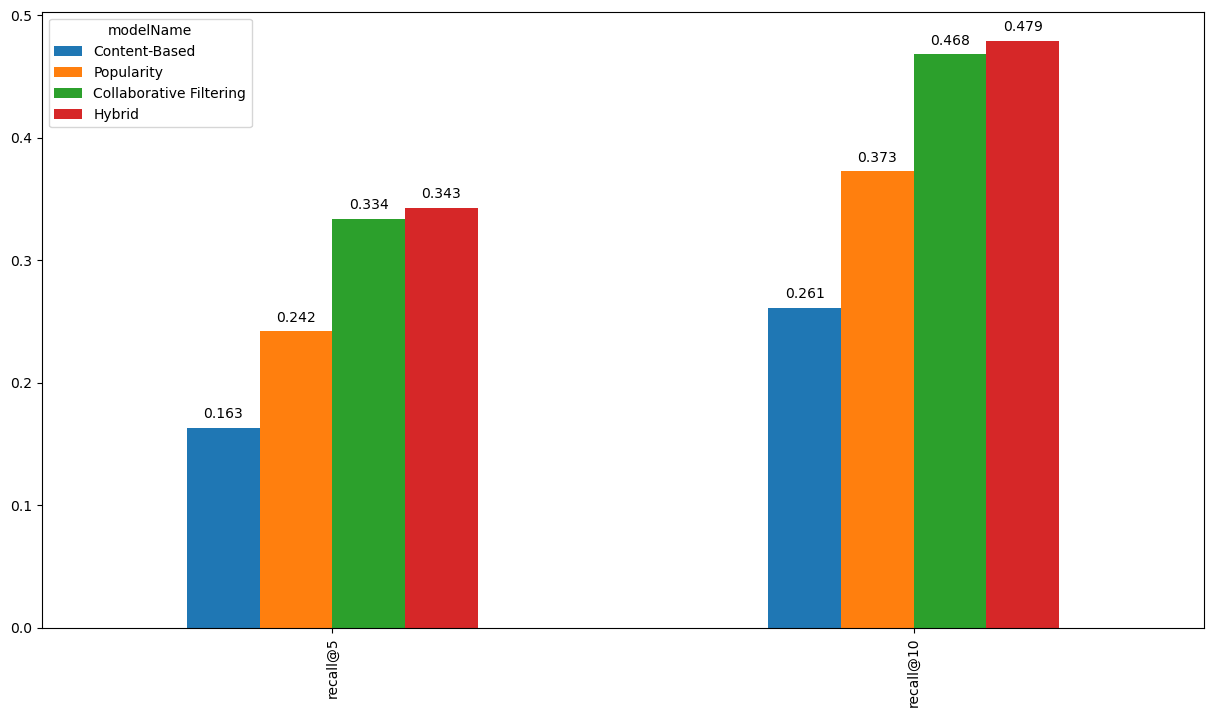 TESTINGNow, we will test the best model, which is hybrid for other users. Some of the articles We engaged with in Deskdrop from Train Set are shown below. It is clear that machine learning, deep learning, artificial intelligence, and the Google Cloud Platform are among key areas of interest. Output: 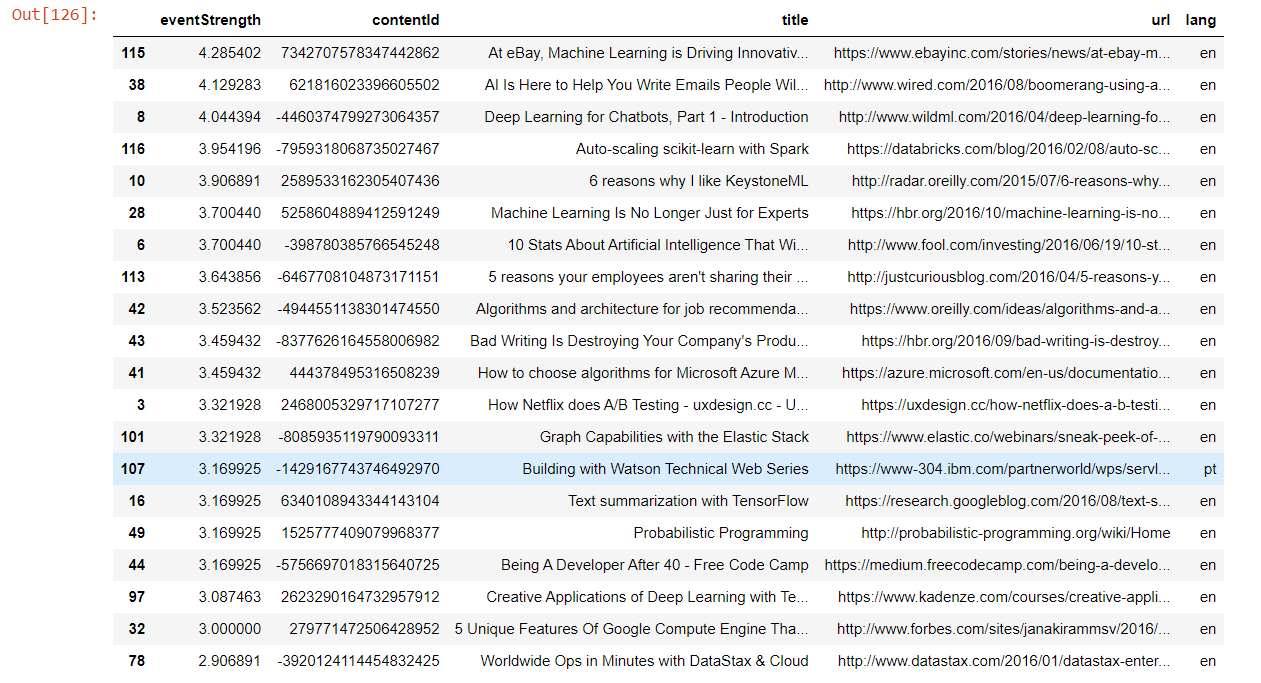 Output: 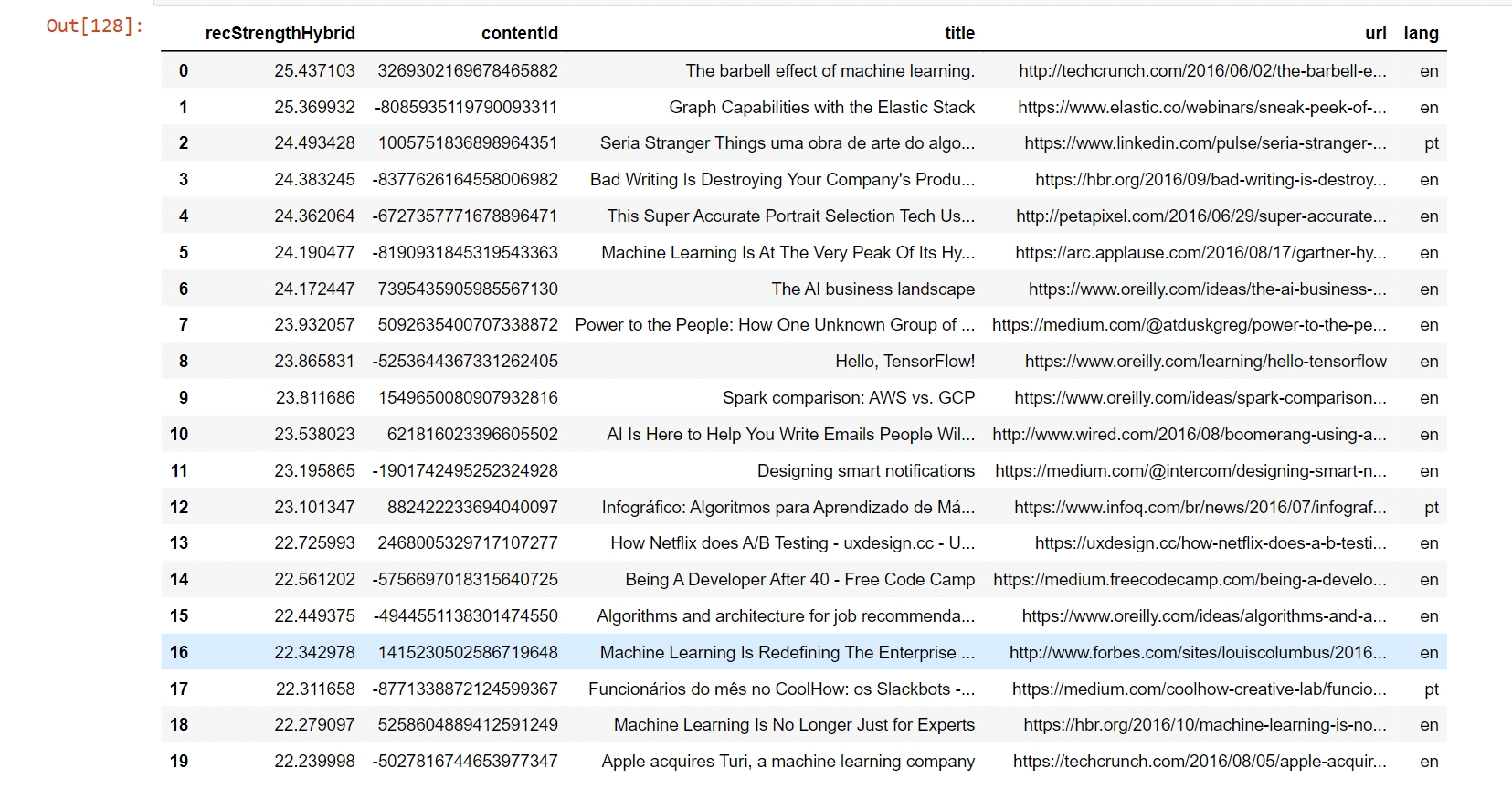 As we check the comparison between the recommendation from the hybrid model and the actual interest, we find that the recommendations are pretty similar. ConclusionIn this article, on the CI&T Deskdrop dataset, we investigated and contrasted the primary recommender system methodologies. It could be shown that content-based filtering and a hybrid strategy outperformed collaborative filtering alone in terms of article suggestions. Among the three, the Hybrid model has the highest accuracy for the best recommendation. |
We provides tutorials and interview questions of all technology like java tutorial, android, java frameworks
G-13, 2nd Floor, Sec-3, Noida, UP, 201301, India






































