| |

Introduction to Trie using PythonA tree-based information structure called a "Trie" is portrayed as being utilized to store assortments of strings and complete speedy pursuits on them. The name "Trie" comes from the action word "Recovery," which indicates the demonstration of finding or securing something. Two strings will have a similar precursor in the Trie if they share a prefix, per a standard that the Trie keeps. A trie might be utilized to look on the off chance that a string with a particular prefix is available in the Trie or not, as well as to sort an assortment of strings sequentially. Need for Trie Data Structure?A Trie information structure is utilized for information capacity and recovery; comparable exercises could be done utilizing a Hash Table information structure. Be that as it may, Trie is more successful at completing these undertakings. Furthermore, Trie has an advantage over the Hash table of its own. Prefix-based looking should be possible with a Trie information structure; notwithstanding, utilizing a Hash table is impossible. A Trie's fundamental structure is a tree-like arrangement in which each Node stands for a single letter or segment of a string. As you move down the tree, characters are added to create whole words or phrases starting at the root node, representing an empty string. Fast and accurate string-based operations are possible because of this hierarchical organization. The Trie's capacity to quickly complete tasks like looking for words with a similar prefix or identifying all terms in a dictionary that meet a specific pattern is one of its distinguishing qualities. Tries are incredibly effective for jobs requiring enormous collections of strings since these operations have a temporal complexity dependent on the query string's length rather than the dataset's size. Additionally, Tries are used in dictionary and autocomplete functions, which enhance user experience in programs like chat platforms, code editors, and search engines. Their effective prefix-matching capabilities enable real-time suggestions, improving the usability and effectiveness of user interactions. There are other types of Tries, such as the regular Trie, compressed Trie, and ternary search Trie, each of which is intended to optimize a particular use case. For example, compressed tries minimize space complexity by combining common prefixes, while ternary search tries are excellent at effectively managing large vocabulary. Attempts have many uses, including IP routing, spell-checking, and natural language processing. Understanding Tries continues to be essential for improving the speed and accuracy of text-related computations and optimizing string-based algorithms. Tries are a crucial data structure that enables effective string-based operations to sum up. Thanks to their adaptability and speed in various applications, they improve the performance of systems that rely on string matching, searching, and indexing. The power of Tries can be harnessed, and algorithms can be optimized for text-related activities in the ever-expanding field of computer science and information technology, but understanding Tries is essential. Trie's information structure enjoys a few upper hands over a hash table. The A trie information structure is better than a hash table in the accompanying ways:
Properties of a Trie Data StructureWe realize that Trie is coordinated like a tree. Along these lines, understanding its characteristics is essential. A few vital qualities of the Trie information structure are recorded below:
Trie Information Design: 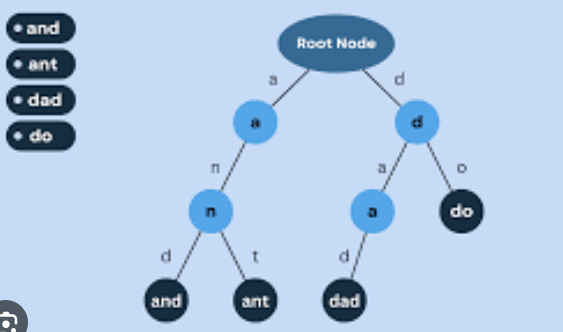
How Can Trie Data Structure Work?We know that any measure of characters, including letter sets, numerals, and extraordinary characters, might be utilized in the Trie information structure. In any case, here, we'll zero in on strings that contain the letters a through z. Hence, every hub requires 26 pointers, where the 0th file means the letter "a" and the 25th record indicates the person "z." Any lowercase English word might start with one of the letters beginning to end, trailed by one of the letters a to z again for the word's third letter, etc. To store a word, we should utilize a cluster (compartment) of size 26. Since there are no words from the outset, the characters in the cluster are all vacant, as seen underneath. 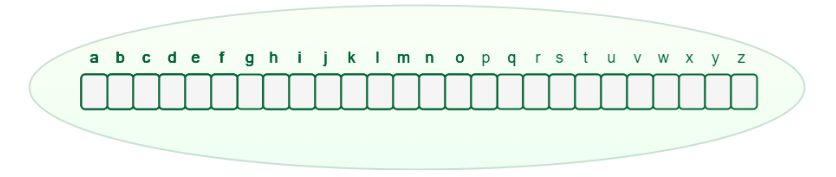
We should perceive how the Trie information structure stores the words "and" and "subterranean insect": 1. In the Trie information construction, store "and":
2. In the Trie data structure, store "ant":
The Trie will appear as follows after the words "and" and "and" have been stored: 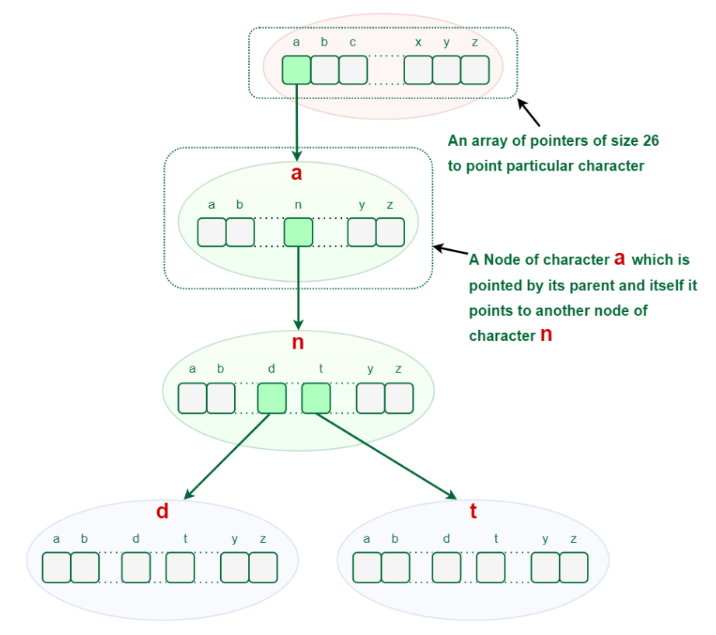
Representation for a Trie Node:Each Trie node comprises a character pointer array or hashmap and a flag indicating whether or not the word ends at that Node. But rather than using a hashmap to create Trie Node, we may use an array if the words only include lowercase letters (i.e., a-z). Basic Trie Data Structure Operations:
1. Trie Data Structure Insertion:This operation adds new strings to the Trie data structure. Let's test this out first: Let's try adding "and" and "ant" to this sentence: 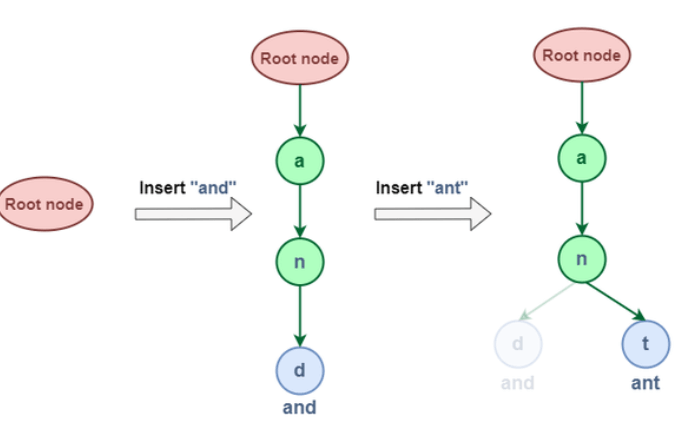
The word "and" and "ant" have a common node (i.e. "an") in the insertion representation shown above. This is due to the Trie data structure's characteristic that if two strings share a prefix, they will have the same ancestor. Let's try inserting "dad" and "do" now: 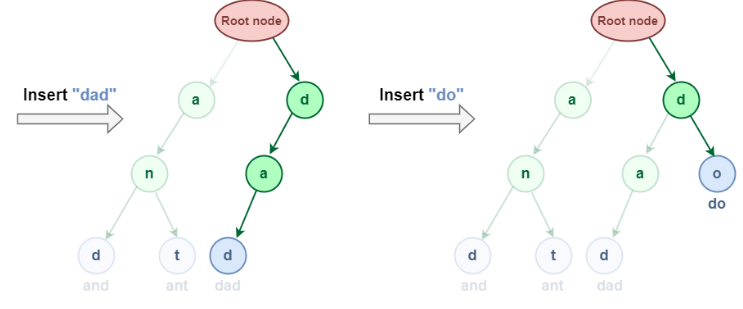
Insertion implementation in the Trie data structure: Algorithm:
The following is the execution of the above calculation: 2. Trie Data Structure search:The main way the pursuit activity varies from the addition activity in Trie is that at whatever point we find that the variety of pointers in the curr hub doesn't highlight the ongoing person of the word, we return misleading instead of making another hub for that person. Utilizing this strategy, you might check whether a string is put away in the Trie information structure. The Trie information structure has two different pursuit techniques.
The two techniques utilize a comparable inquiry design. Changing a word over completely to letters and contrasting every one and a trie hub from the root hub are the underlying strides in a Trie look for a given word. Proceed to the hub's kids, assuming the ongoing person is tracked down there. Keep doing this until all characters are found. 2.1 Trie Data Structure Prefix Search: Look for the prefix "an" in the Trie Data Structure. 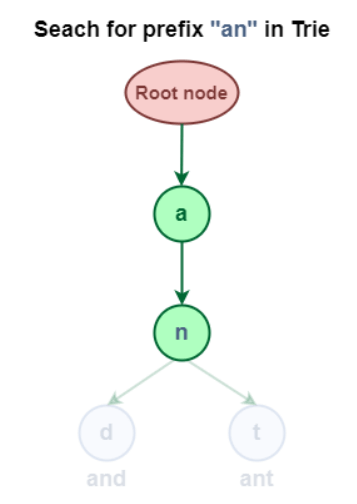
Prefix Search implementation in the Trie data structure: 2.2 Complete word search in the Trie Data Structure: It is similar to prefix search, but we must also determine if the word ends at the final character. 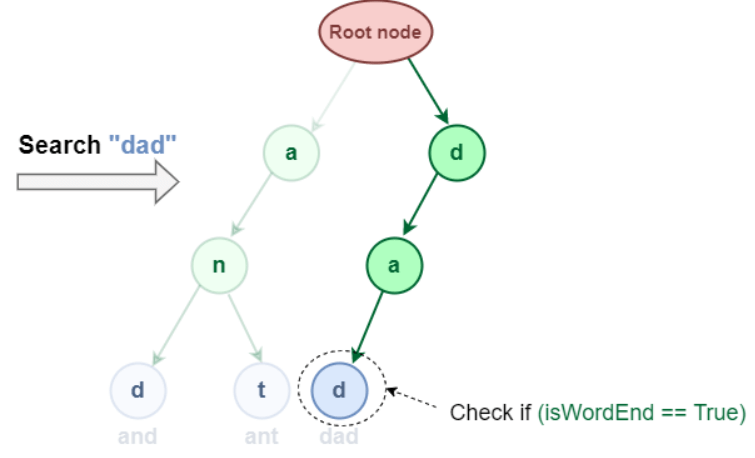
Using the Search algorithm with the Trie data structure: 3. Trie Data Structure DeletionStrings can be removed from the Trie data structure using this method. When removing a word from Trie, there are three scenarios.
Example: 3.1 The removed word functions as a prefix for additional Trie words. The deleted word "an," as seen in the accompanying graphic, shares a full prefix with the words "and" and "ant." 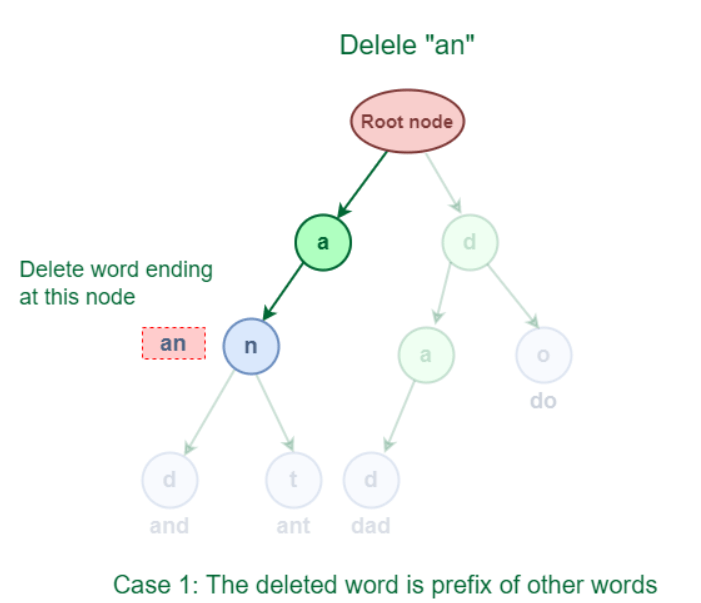
Reducing the word count by 1 at the word's ending Node will execute a delete operation in this situation. 3.2 The eliminated word has a prefix in common with other words in Trie. As seen in the accompanying image, the deleted word "and" has several prefixes, with other words beginning with "ant." They both start with "an." 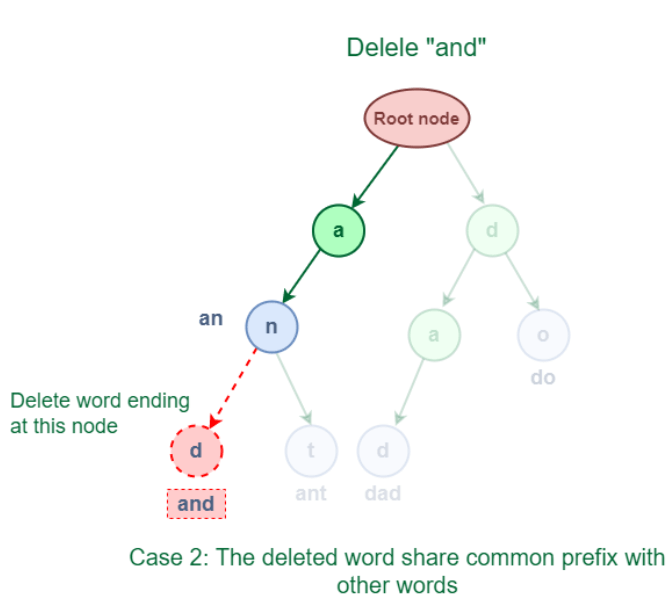
3.3 There is no prefix that the deleted word has in common with any other Trie terms. As seen in the accompanying diagram, the term "java" does not share a common prefix with any other words. 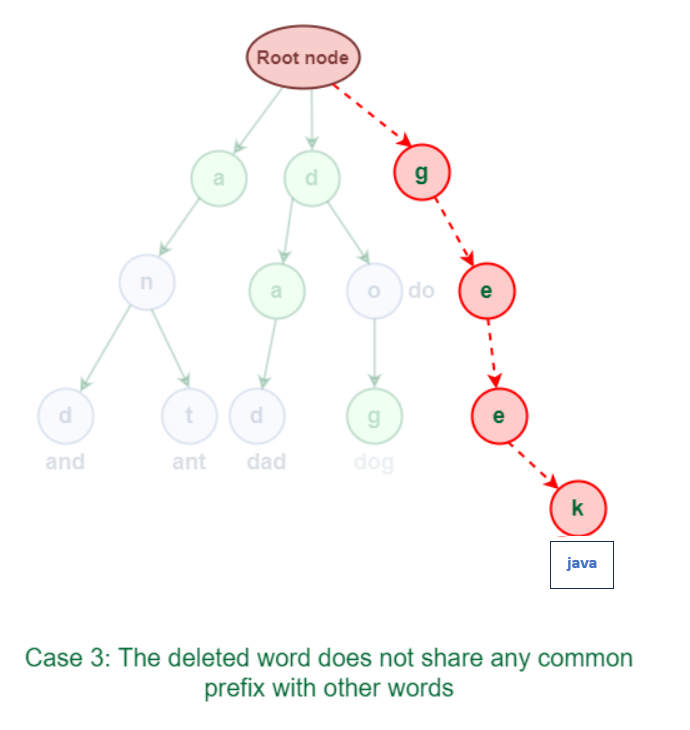
Simply deleting every Node will solve the problem in this instance. The implementation that manages all the circumstances mentioned above is shown below: How is the Trie Data Structure implemented?
Output: Query String: do The query string is present in the Trie Query String: java The query string is present in the Trie Query String: bat The query string is not present in the Trie Query String: java The query string is successfully deleted Query String: tea The query string is not present in the Trie Analysis of the Trie Data Structure's Complexity
Note: In the complexity chart above, "n" and "m" stand for the string length and the quantity of strings kept in the Trie, respectively.Applications of the Trie data structure include:1. Autocomplete Feature: The autocomplete feature offers suggestions depending on the search terms you enter. The autocomplete feature is implemented using the trie data structure. 
2. Spell checkers: They offer suggestions based on what you entered if the term does not appear in the dictionary. There are 3 steps to it, which are as follows:
Trie saves the dictionary data, facilitates the development of search algorithms for dictionary terms, and offers a list of acceptable words for suggestion. 3. Maximum Prefix Length Match: It is often known as the longest prefix-matching algorithm and is a routing technique used in IP networking. Contiguous masking, which limits search time complexity to O(n), is necessary for network route optimization. n is the length of the URL address in bits. Multiple Bit Trie methods were created to expedite the search process by doing multiple-bit lookups more quickly. Advantages of Trie Data Structure:
Disadvantages of Trie Data Structure:
|
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








