| |
Python Tutorial
Python OOPs
Python MySQL
Python MongoDB
Python SQLite
Python Questions
Plotly
Python Tkinter (GUI)
Python Web Blocker
Python MCQ
Related Tutorials
Python Programs

Working with PDF files in PythonAs in today's world, we all are familiar with PDF files because they are one of the most widely used digital formats of documents. The full form of pdf is "Portable Document Format," which uses the ".pdf" extension to save the document files. This is independent of software-hardware or operating systems, and it can be used for presenting or exchanging documents reliably. PDF was invented by Adobe, and this is now an open standard maintained by the international organization for standardization. The PDF file can also contain links or buttons form fields, audio-video, or other business logic for better interaction with the users or the viewers. In this tutorial, we will discuss how we can perform various operations:
We can perform all these operations by using a simple Python script. InstallationFor interacting with PDF files, we will be using a 3rd party module, that is, PyPDF2. The PyPDF2 is an inbuilt library of Python, which is used as a PDF toolkit. This module is capable of:
For installing PyPDF2 we can use the following command from the command line: The name of this module is case-sensitive, so we have to make sure that the "y" is in lowercase and everything in the name of the module is in uppercase. Operations on PDF File using PyPDF2 ModuleIn this section, we will discuss various operations that we can perform on PDF files by using the PyPDF2 module in Python. 1. How to Extract Text from PDF Document File.We can extract the text from the PDF file by using the PyPDF2 module in Python by using the following approach. Approach: For extracting the text from the PDF file using Python, we will follow the following steps: Step 1: We will open the PDF file named 'exp.pdf' in binary mode and save the file object as "pdf_File_Object". Step 2: We will create an object "pdf_Reader" for the "PDFFileReader" class of the "PyPDF2" module, and then we will pass the PDF file object and get the object for reading the PDF. Step 3: For getting the number of pages in the PDF document file, we will use the numPages Step 4: We will create an object "page_Object" for PageObject class of the "PyPDF2" The PDF reader object has the function "getPage()" which takes the page number as an argument and returns the object of the page. Step 5: We will use extract text which is a function of page object for extracting text from the PDF page. Step 6: At last, we will close the PDF document file object. Code: Output: No. of pages in the given PDF file: 10 GUIDELINES * FOR RE - OPENING OF CAMPUS IN VIEW OF COVID - 19 PANDEMIC (FOR STUDENTS ) 2021 - 22 This has printed the text of the first page of the PDF file in output. 2. How to Rotate PDF File PagesWe can rotate the pages of PDF file using PyPDF2 module in Python. Approach: For rotating the pages of the given pdf file, we will be using the following steps: Step 1: We will create a PDF reader object for the original PDF. Step 2: We will write the rotated pages to the new PDF file. For writing Into the PDF file, we will use the object of the pdfFileWriter class of the PyPDF2 Step 3: We will iterate each page of the original PDF document file. We will get page object getPage() function of the PDF reader class. then we will rotate the page by using the rotateClockwise() function of the page object class. Step 4: We will add pages PDF writer object using the addPage() function of the PDF writer class by passing the rotated page object. Step 5: Then, we will write the PDF pages to the newly created PDF file. We can do this by opening the new file object and writing PDF pages by using the write() function off the PDF writer object. Step 6: We will close the original PDF file object end the newly created new file object. Code: Output: Original File: 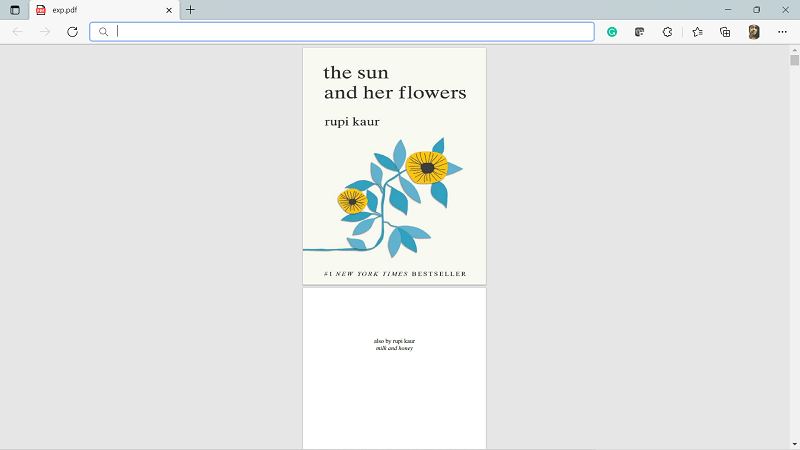
Rotated File: 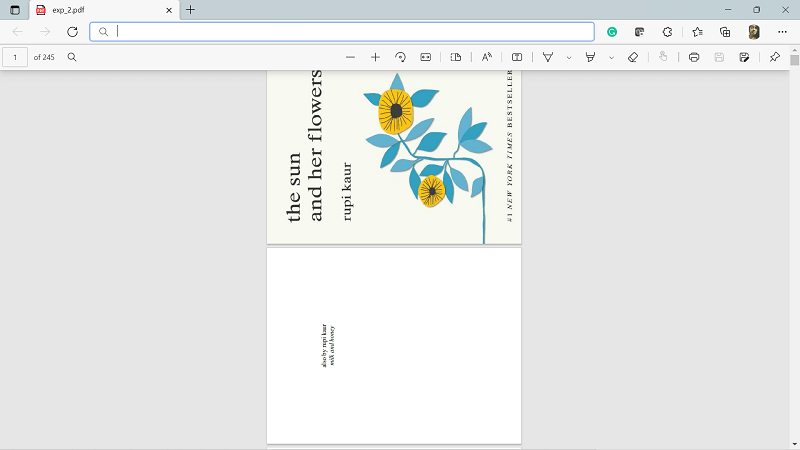
3. How to Merge two PDF Files.We can merge two PDF files by using the PyPDF2 module in Python. Approach: For merging two PDF files in Python, we will be using the following steps: Step 1: For merging two PDf files, we will be using a pre-built class, pdfFileMerger of the PyPDF2 Step 2: Then, we will append the file object of each PDF to the PDF merger object using the append() Step 3: At last, we will write the pdf pages to the output pdf file by using the write method of the PDF merger object. Code: Output: The output of this code will be in the form of a combined PDF named combined_exp.pdf, which is obtained by merging exp.pdf and rotate_exp.pdf file. 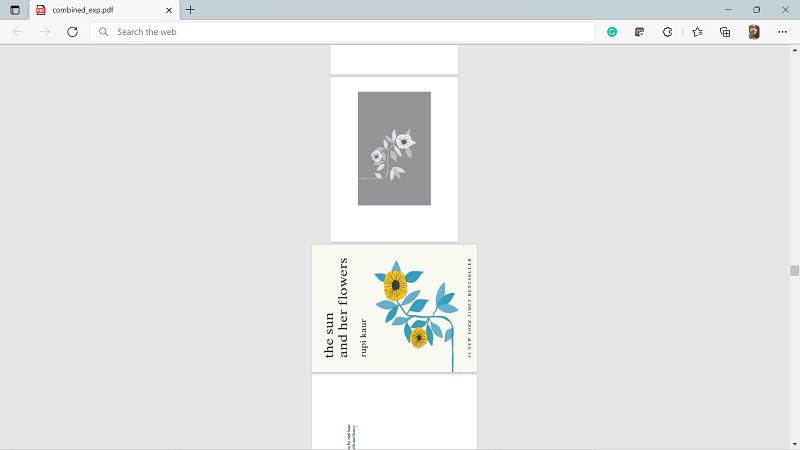
4. How to Split PDF FileWe can split the PDF document file in Python using the PyPDF2 module according to our requirements. In this code, we will not use a new function or class, and we will be using simple logic and iterations. The splits of the pdf will be created according to the list of splits_1 we would be passing. Code: Output: The output of this code will generate 3 new pdf files, which are the split files of the main pdf. We can check in the PDF folder. It contains 3 new pdf files. 
5. How to Add Watermark to PDF Pages.We can add watermark to the pages of PDF document files using the PyPDF2 module in Python. Approach: In this, we will follow every step same as the page rotation example, the only difference is: The page object will be converted into the watermark page object by using the add_watermark() function. For understanding what the add_watermark() function do, we can see the following example: In this, first, we created a pdf reader object of the water_mark.pdf file. For the passed page object, we have used the mergepage() function, which has passed the page object of the first page of the water_mark pdf reader object. This will cause an overlay of water_mark pdf over the passed page object. Code: Output: water_mark.pdf: 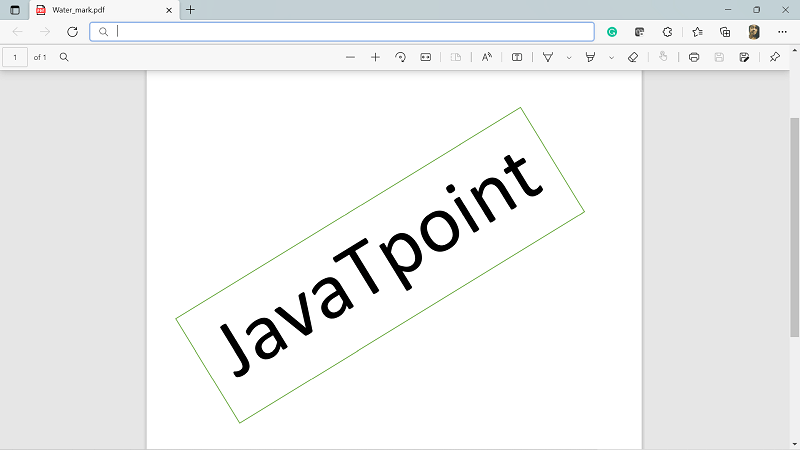
user_watermark.pdf file: 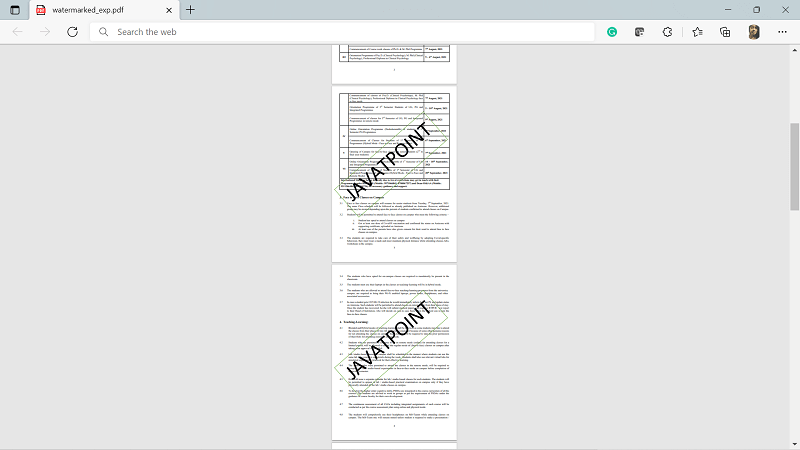
The above code will generate a user_Watermark.pdf file which has the watermark of the water_mark.pdf file. ConclusionIn this tutorial, we have discussed how we can operate different functions on PDF files using Python and its modules' functions and methods.
Next TopicPDF Handling in Python
|
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








