| |

Sentiment Analysis using NLTKData is being produced at an astounding rate and volume in the field of the internet and other digital services nowadays. Researchers, engineers, and data analysts often work with tabular or statistical data. There may be categorical or numerical data in each of these tabular data columns. Various data formats, including text, picture, video, and audio, are present in data that is generated. Analysis of unstructured data is produced by online behaviour such as publications, web content, blog entries, and social media platforms. To effectively build their business, corporations and businesses must examine textual data to comprehend consumer behaviours, opinions, and comments. Text analytics is developing at a higher pace in order to deal with massive text information. Sentiment Analysis: what is it?The method of determining how well a chunk of content is good, negative, or neutral is known as sentiment analysis. Sentiment analysis is just the contextually extraction of words that reveals the social attitude of a brand and aids businesses in determining if the products they are producing will find a market. Sentiment analysis's objective is to examine public sentiment in a manner that will support corporate growth. What is the Process of Sentiment Analysis?The first approach is Automatic Method. This strategy utilises the machine learning method. Predictive analysis is first performed once the datasets have been processed. Word extracting from either the text is the subsequent procedure. Different methods, including Naïve Bayes classifier, Regression Analysis, Support Vector, and Machine Learning algorithms, could be used to analyse text, just like these machine learning approaches. The second approach is Rule-based strategy Here, rule-based tokenization, parsing, and the lexicon technique are used. The strategy counts how many positive and negative terms are present in the sample. If there are more positive messages than negativity, the emotion is positive; otherwise, it is the opposite. The most accurate method for sentiment analysis is Hybrid Approach. This method combines the rule-based and automated procedures described above. The advantage is that, in comparison to other major procedures, accuracy will be great. Sentiment Analysis: Why do it?Large amount of the data in the globe is unstructured, in accordance with the report. Regardless matter whether the data exists in the form of email messages, papers, websites, or anything else, it has to be examined and organised. For instance, what if we wanted to determine how well a product was meeting client needs or if there was a market demand for it? We can track the comments for that product using sentiment analysis. When we have big amount of unstructured data and we wish to categorize that data by manually labelling it, sentiment analysis is very effective to apply. 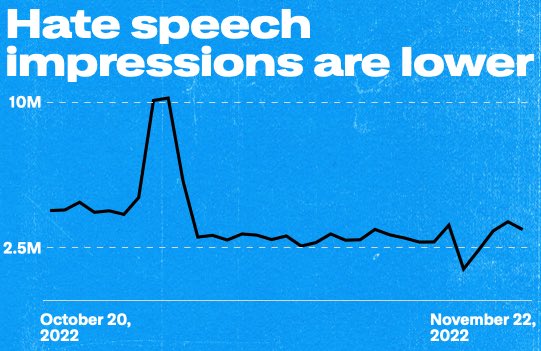
Post shared by Elon musk on twitter about hate speech analysis in November 2022 NLTK LibraryNumerous tools that you may use to efficiently handle and analyse linguistic data are available in the NLTK library. Text classifications, which may be used for a variety of classifications, particularly sentiment analysis, are some of its sophisticated features. The technique of sentiment analysis consists of categorising testing is performed of linked text into broad favourable and negative classifications using algorithms. To get ideas from linguistic data, you may use these methods with NLTK using robust constructed machine learning procedures. Basic Procedure:
Use Guidelines for NLTK Sentiment AnalysisSentiment analysis is a type of data analysis that extracts and interprets subjectively data from the Internet, particularly from social networking sites and other relevant sources, using NLP, computational linguistics, and text categorization. to investigate the majority's attitudes or emotions toward particular subjects, people, or thoughts and to identify the situational polarity of the evidence. We'll use the well-liked NLP tool for Python called NLTK to examine text data. There are mainly two approaches to sentiment analysis. based on the Lexicon It counts the number of positive and negative phrases included in a particular text; the higher the score, the more upbeat the text is. Text categorization is among the most critical tasks in text mining. It's a technique that has undergone extensive observation. determining the genre or type of a work, including a weblog, a magazine, a website, news articles, or tweets. Applications for it in the modern computer world include spam identification, task classification in CRM systems, classifying website contents for search engines, American customer satisfaction analysis, and others. We need to import the NumPy, pandas, matplotlib, and seaborn modules into our code before we can apply NLTK sentiment analysis. The demo below demonstrates well how incorporate the following modules within our program. Code Classifiers for Sentiment Analysis in NLTKEmotion analysis is the technique of figuring out how an author feels about a subject they are writing about. To train a model, we must create a training data set. It was a supervised machine learning process that demands us to give each training dataset a "sentiment." In this lecture, our model employs both "positive" and "negative" attitudes. Sentiment analysis could be used to categorise text into a variety of emotions. A system that will be defined by a set of guidelines and equations called a model. It might be anything as simple as a formula that calculates a bodyweight depending on their height. A sentiment analysis approach that relates tweets to either positive or negative emotion will be developed. Our content will have to be split into two halves. The first part's objective is to create the model, and the second part's objective is to evaluate the performance of the model. The NLTK's Naive Bayes classification will be used to finish the modelling experiment. A Python dictionaries containing words as both keys and values is necessary for the models. Sentiment Analysis Concept Approaches Using NLTKThe NLTK sentiment concept analysis technique is demonstrated in the following phases. Import the Module FirstThrough using import keywords, we load the modules for pandas, NumPy, matplotlib, and seaborn throughout this stage. Equations involving linear algebra are handled by the NumPy module. Analysis of documents is done using the Panda module. For improved visualisation, the Matplotlib package is utilised. For improved visibility, the Seaborn modules is also employed. The importing of the module is demonstrated in the instance below. Code DatasetFor dataset we can use flipkart review data 2022_02 . The data is stored in a menu option file. The data set is made up of several columns that we've utilised. Code Output: 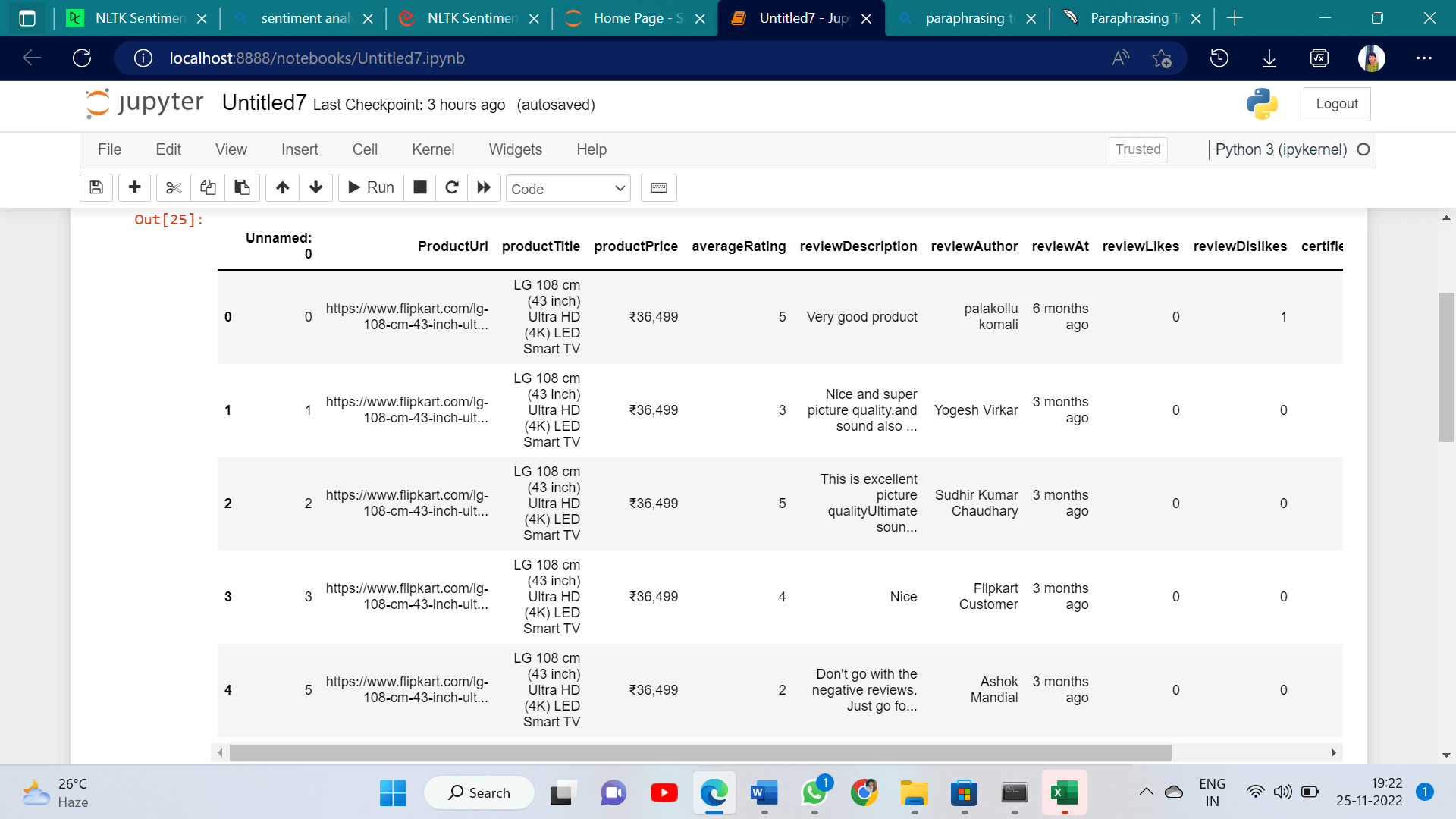
Using the info method, we examine the csv file's information. We are utilising the object of x with the info method. The display information of the csv file is shown in the sample below. Code Output: < class ' pandas.core.frame.Data Frame' > Range Index : 25 entries, 0 to 24 Data columns ( total 12 columns ): # Column Non-Null Count Dtype --- -- -- -- -- --- ---- --- -- -- --- 0 Unnamed: 0 25 non-null int64 1 Product URL 25 non-null object 2 product Title 25 non-null object 3 product Price 25 non-null object 4 average Rating 25 non-null int64 5 review Description 25 non-null object 6 review Author 25 non-null object 7 review At 25 non-null object 8 review Likes 25 non-null int64 9 review Dislikes 25 non-null int64 10 certified Buyer 25 non-null bool 11 reviewer Location 25 non-null object Dtypes : bool(1), int64(4), object(7) memory usage : 2.3+ KB AnalysisFinal step is sentiment analysis of the flipkart reviews that is shown in the form of reviews and rating. The rating will imply the average users feelings. If the user gives very less rating, then it is obvious that the user is not satisfied with the products from the company. Or the user gives very huge rating, then it implies that the customer is exhilarated by the product. The code implementation of the above flipkart reviews dataset can be shown with the help of a bar plot in the below manner. Code Output: 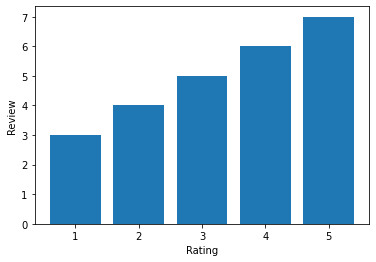
ConclusionSentiment analysis is the technique of employing computers to group several connected text examples into different groups. These methods use the advanced built-in machine learning algorithms of NLTK to order to understand the dynamics from linguistic data. For instance, NLTK sentiment classification can help us determine the amount of positive and negative participation on a certain problem.
Next TopicDesktop Battery Notifier using Python
|
 For Videos Join Our Youtube Channel: Join Now
For Videos Join Our Youtube Channel: Join Now
Feedback
- Send your Feedback to [email protected]
Help Others, Please Share








